https://wikibook.co.kr/reinforcement-learning/
파이썬과 케라스로 배우는 강화학습: 내 손으로 직접 구현하는 게임 인공지능
“강화학습을 쉽게 이해하고 코드로 구현하기” 강화학습의 기초부터 최근 알고리즘까지 친절하게 설명한다! ‘알파고’로부터 받은 신선한 충격으로 많은 사람들이 강화학습에 관심을 가지
wikibook.co.kr
해당 포스팅은 위의 책을 보고 정리한 내용입니다.
제 마음대로 하는 제목이지만, 강화학습 기초->기본으로 넘어왔습니다.
이전 포스팅까지는 강화 학습을 하기까지의 개념과 배경을 알아왔고, 이제부터 학습의 영역이라고 생각 했기 때문입니다.
MDP라 부르는 마르코프 결정 과정(MDP 포스팅: https://wnthqmffhrm.tistory.com/4?category=906651)에 기반한 연속적인 의사 결정 문제를 푸는데 고전적인 방법인 다이나믹 프로그래밍은 3가지의 한계점이 있었습니다.
- 계산복잡도: 다이나믹 프로그래밍의 계산복잡도는 O(n^3)입니다.
- 차원의 저주: 상태 S의 차원이 늘어날 수록 상태의 수는 지수적으로 증가합니다.
- 환경에 대한 완벽한 정보가 필요: 다이나믹 프로그래밍을 이용해서 풀때, 보상과 상태 변환 확률을 정확히 안다는 가정하에 풀게됩니다.
아래의 벨만 기대 방정식을 풀기 위해서는, 그 아래 상태 변환 확률이 꼭 알아야 합니다. 상태 s에서 행동 a를 했을 때, 다음 상태 S_t+1에 영향을 끼치는 요소이기 때문이죠.(벨만 방정식 포스팅: https://wnthqmffhrm.tistory.com/5?category=906651)
하지만 실제 문제에서 환경에 대한 요소를 완벽하게 알기는(또는 공식화)하기에는 무리가 있죠 - 3번 한계.
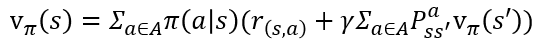
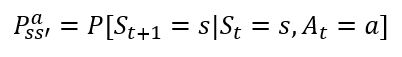
설상 환경을 완벽히 알아도(또는 상태 변환 확률을 1로 가정) 바둑같은 수많은 상태를 고려해야하는 문제에서는 너무 많은 계산이 요구됩니다 - 1,2번 한계.
그럼 그리드 월드같은 환경이 작고 간단한 문제만 풀 수 있는 걸까요?
당연히 아니기 때문에 강화학습이 발전했습니다.
사람들은 이 문제를 완벽하게 풀려고 하지 않고, 근사를 통해 풀어 나갑니다.
들어가기 전에 한가지 예시를 더 들자면, 축구를 할 때, 공마다 다른 탄성, 날씨에 따른 바람 세게, 자신의 컨디션을 완벽히 통제하에 두고 공을 차는 사람은 없습니다. 그날 차보고 공에 바람이 너무 많으면 조금 약하게 차고, 바람이 세게불면 깔아차고 그러는 것이죠.
이러는 개념이 바로 근사를 통해 풀어 나간다는 개념이랑 일맥상통함이 있습니다. 바로 해보고 판단하는 것이죠.
서론이 길었습니다.
그럼 어떻게 근사하느냐? 바로 몬테 카를로 근사(Monte Carlo Approximation)를 통해서 입니다.
어려운 이름에 겁먹으실 필요 없습니다. 핵심은 "엄청 많이 시도해보면, 정답을 알 수 있다!"입니다.
아래 그림은 넓이가 1인 직사각형에 걸쳐진 1/4 원의 넓이 몬테 카를로 근사를 통해 구하는 과정입니다.
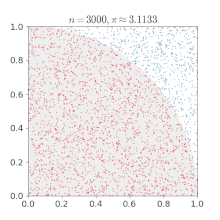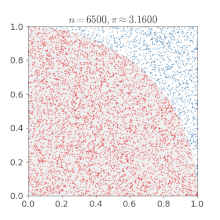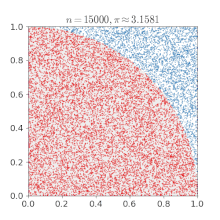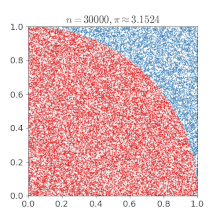
직사각형(환경)에 무작위로 수많은 점(시도)들을 찍습니다. 그리고 충분히 많은 점을 찍혔을때, 원 안에 들어간 점과 전체 점의 비율로 넓이를 곱해주면 정답에 근사한다는 것이 몬테 카를로 근사 입니다. 즉, 사각형의 넓이 * (원 안에 들어간 점/전체 점) =~ 1/4 원의 넓이가 되는것이죠. 조금 무식하지만 무한개의 점이 찍힌다면 충분히 말이 됨을 잘 따라오셨다면 이해하실 수 있을 겁니다. (이때 =~는 거의 같다 입니다.)
"원의 방정식이 있는데, 왜 이렇게 무식하게 구하냐!" 하실 수 있습니다. 하지만 우리는 더 복잡한 도형(환경)의 문제를 풀고자 하는 사람입니다. 문제가 복잡해질수록(공식화 하기 어려울 수록, 환경을 알기 어려울수록) 이 근사 방법이 필요해지는 것입니다.
환경을 그리드 월드로 바꾸고, 수많은 점을 수많은 시도(에피소드)로 바꾸면, 똑같이 적용이 됩니다.
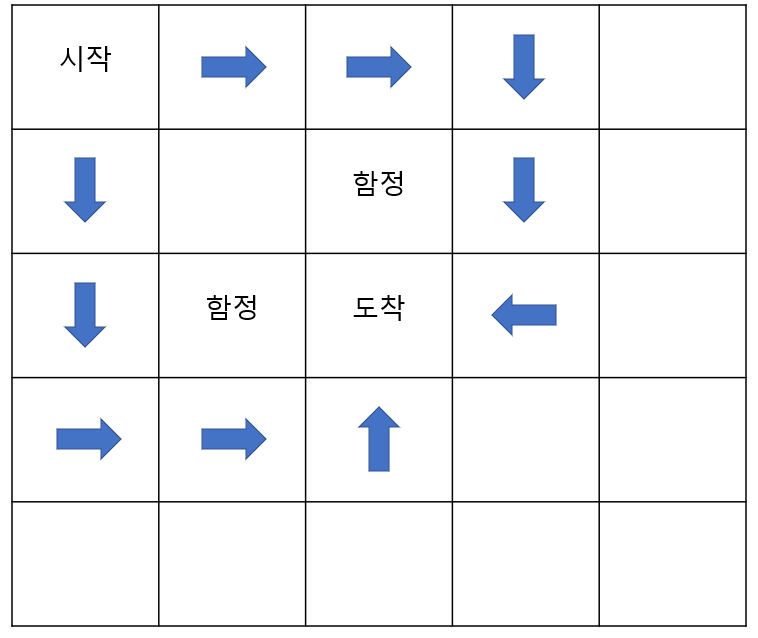
환경을 몰라도 아래와 같이 다양한 시도를 하고, 여러 에피소드를 통해 구한 반환값의 평균을 통해 벨만 기대 방정식을 추정하는 것이죠. 그림 아래 수식은 에피소드를 통한 벨만 기대 방정식 추정을 나타 냅니다. N(s)는 상태 s를 여러 번의 에피소드 동안 방문한 횟수이고, G_i(s)는 그 상태를 방문한 i번째 에피소드에서의 s의 반환값 입니다.
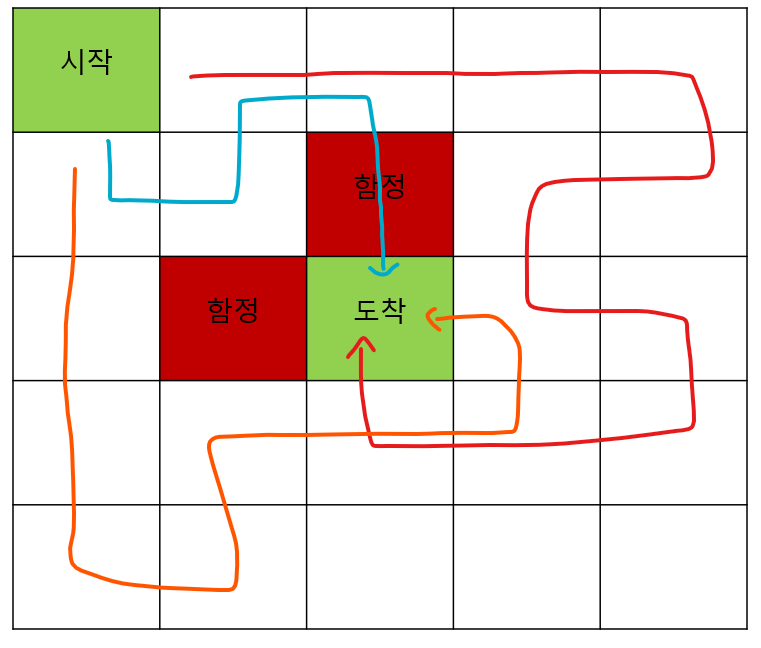
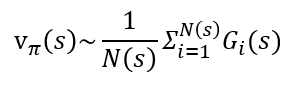
위 그림에는 3가지 에피소드만 표현했지만, 무수히 많은 시도를 하게되면 결국 할인율을 적용한 보상에 의해 최단 거리로 도착했을때 보상이 가장 커지고 그런 상태에 가깝게 통과되는 지점에 대한 보상이 커질 것입니다.
그렇게 되면 큰 보상을 따라가는 정책에 의한 행동이 강화될 것입니다.(아직 포스팅 하지 않은 ε-greedy라는 정책일 때 가정, 몬테 카를로 근사를 적용하는데 적절한 정책으로 이해하시면 됩니다.)
위에서 설명한 것과 같이, 설명한 수많은 시도를 통해 결국 정답에 가깝게 되는 것입니다. 따라서, 에이전트는 결국 함정을 피하지만 최단거리로 도착하게 하는 것에 맞춰 가치함수가 업데이트 될 것을 예상 할 수 있습니다.

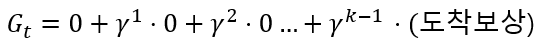
여기까지 따라오셨다면 (적어도 그리드 월드에서), 몬테 카를로 근사를 통해 다이나믹 프로그래밍이 아니더라도 적절한 가치함수를 구할 수(가까워질 수)있다는 것을 큰 틀에서 아셨을 겁니다.
이제 정확히 어떤 방식으로 상태 s에서의 가치함수가 업데이트 되는지 설명하겠습니다.
아까 언급한 이 수식은 아래와 같이 풀어질 수 있습니다. 이제, 추정한 가치함수를 나타내므로 소문자 v 가 아닌 대문자 V로 표기하고 방문환 횟수 N(s)는 n으로 표기합니다. 아래의 수식을 보면 업데이트 될 가장 좌측의 V_n+1은 가장 우측처럼 n번째 현재의 반환값 G_n과 이전의 반환값 ΣG_i으로 나누어 진것을 확인할 수 있습니다.
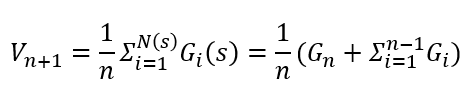
이 식을 좀더 풀어보면 아래와 같습니다. 우선 (n-1)/(n-1)을 Σ옆에 곱해줍니다. 두 수는 서로 나누어져 1이므로 등호는 성립합니다.
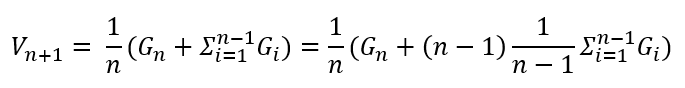
이렇게 되면, 위의 업데이트 할 가치함수 V_n+1을 나타내는 식에서,
업데이트 되기 전인 현재 가치함수 V_n를 찾을 수 있게 됩니다. 그 식은 아래와 같죠.
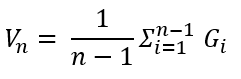
위의 식을 V_n+1에 적용하면 아래와 같이 나타낼 수 있습니다.

이 식을 조금 더 정리하면 아래와 같이 정리 될 수 있습니다. 식의 모양은 많이 바뀌었지만 아래의 식 모드 등호로 이루어져 V_n+1을 나타냄은 변함 없습니다. 이렇게 정리된 식을 보면 알 수 있는 것은 업데이트 될 V_n+1는 현재 가치함수 V_n과 이번 에피소드를 통해 얻은 반환값 G_n의 차이를 현재 V_n에 더해주는 것입니다. 1/n만큼 나누어진 크기로 말이죠. (이는 딥러닝에서 learning rate를 떠올리게 합니다.) 이렇게 평균을 업데이트 해나가는 것이 이동 평균이라고 합니다.
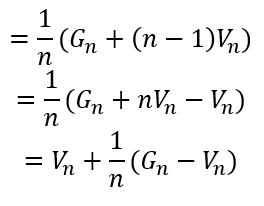
만약 G_n이 고정이고 V_n과 차이가 많이 나더라도 n번만큼 시도하면, n=1일 때와 같습니다. 결국 V_n = G_n이 될 것입니다. 조금 바꿔서, 수많은 에피소드를 통해서 환경은 모르지만 그 환경에서의 확률 공식을 적용하여 푼것과 매우 근사한V_n을 얻을 수 있을 것입니다. 그렇다면 V_n =~ v_n이 되는 것이죠. 이는 위에 예시 같이 수 많은 점들을 통해 결국 원의 넓이를 근사한 것과 다를게 없습니다.
여기서 1/n은 상수 α로 대체되어 쓰이기도 합니다. 환경이 계속 변화하면 시도가 많이질 수록 변화가 작아지는 1/n보다 α같은 고정된 상수로 업데이트 하는 것이 유리하기 때문이죠.
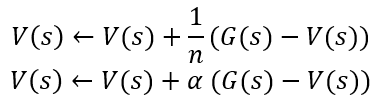
이제 다이나믹 프로그래밍과 달리 환경에 대한 정보 없이도 몬테카를로 근사를 통해 에이전트는 현재 정책에 참 가치함수에 수렴해 갈 수 있습니다.
이때 최종 목표인 최적 가치함수가 아닌 참 가치함수라고 언급한 이유는 현재의 정책이 랜덤으로 고정이 되있을 수 있고, 또한 가장 큰 가치 함수만 선택하는 탐욕 정책을 쓰더라도(Greedy Policy), 함정을 피해 도착한 에피소드에 과적합(over-fitting)되기 때문입니다. (혹시 잘 따라오시다가 바로 이 문장만 이해가 가지 않으시면, 그럴 수 있으니 그냥 넘기셔도 됩니다. 위의 문제를 피하기 위해 쓰인 방법은 다음 포스팅(ε-greedy 정책: https://wnthqmffhrm.tistory.com/8)에 언급 될 거 같습니다.)
긴 글 읽어주셔서 감사합니다.
'강화 학습' 카테고리의 다른 글
| 강화 학습 기본 - 시간차 학습(Temporal-Difference Learning) part 1. 살사(SARSA) (1) | 2022.01.09 |
|---|---|
| 강화 학습 기본 - ε-탐욕 정책(ε-greedy Policy) 그리고 ε-decay (0) | 2022.01.07 |
| 강화 학습 기초 - 다이나믹 프로그래밍의 한계(Limitation of Dynamic programming) (2) | 2022.01.05 |
| 강화 학습 기초 - 정책(Policy), 가치 함수(Value Function) 그리고 벨만 방정식(Bellman Equation) (4) | 2022.01.05 |
| 강화 학습 기초 - MDP(마르코프 결정 과정, Markov Decision Process) (2) | 2022.01.04 |



