https://wikibook.co.kr/reinforcement-learning/
파이썬과 케라스로 배우는 강화학습: 내 손으로 직접 구현하는 게임 인공지능
“강화학습을 쉽게 이해하고 코드로 구현하기” 강화학습의 기초부터 최근 알고리즘까지 친절하게 설명한다! ‘알파고’로부터 받은 신선한 충격으로 많은 사람들이 강화학습에 관심을 가지
wikibook.co.kr
해당 포스팅은 위의 책을 보고 정리한 내용입니다.
다음 포스팅 전에 ε-greedy 정책에 대해 포스팅 해보려 합니다
직전 포스팅인 몬테카를로 근사를 설명하면서 이 부분도 병렬적으로 이해가 되어야 도움이 될거 같습니다.
- ε-greedy 정책
강화 학습에서 에이전트는 주로 greedy 정책을 사용합니다. 학습하면서 얻은 가치 함수 중 가장 큰 값을 따라가는 것이죠. 이 방식은 테스트 단계에서는 당연하지만, 학습 단계에서는 더 다양한, 더 나은 에피소드를 찾아야되기 때문에 greedy 정책을 사용하여 학습 시 문제가 생깁니다. 아래 수식에서 행동 가치 함수 q는 추정한(근사한) 값이기 때문에 대문자 Q로 표기합니다.
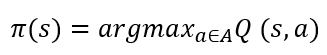
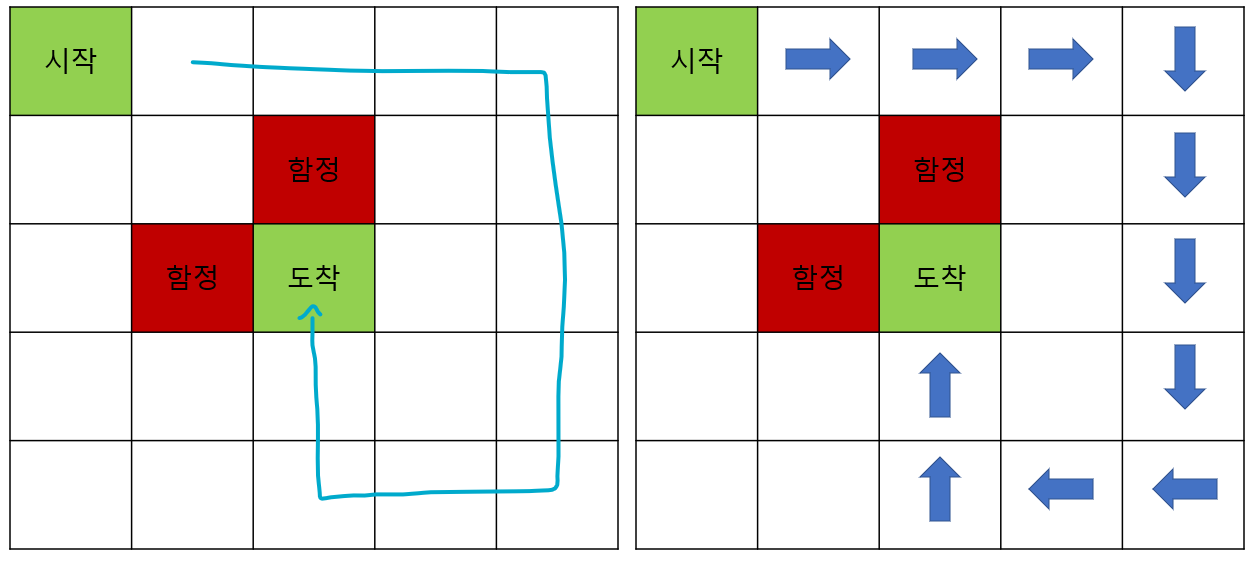
위의 사진 같이 하나의 에피소드가 끝나면, 에이전트는 도착을 성공한 에피소드가 현재 아는 최선의 방식일 것입니다. 이때 greedy 정책을 사용하게 되면 계속해서 같은 길로만 갈 수 밖에 없습니다. 에이전트 입장에서 시작 상태부터 도착 상태까지의 가치함수가 가장 높은 행동은 파란색 화살표로 된 부분이니까요. 이런 문제를 과적합(Over-fitting)문제라고 저는 이해 했는데요. 따라서 에이전트는 더 나은 길을 찾기 위해 학습 과정에서 탐험(Exploration)을 통해 가보지 않은 길도 가야합니다. 이 부분을 적용한 것이 바로 ε-greedy 정책입니다.
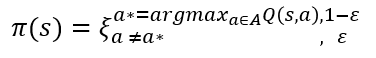
ε-greedy 정책은 위에 수식과 같이 나타 낼 수 있는데요.
ε의 확률로 가장 큰 Q(s,a)를 따라가지않고, 위에서는 파란 화살표를 따라가지 않고 다른 길을 찾는 것 입니다. 하지만 1-ε의 확률로는 그 길을 그대로 따라가는 것이죠. 어느정도는 결과를 신뢰하지만 또 어느정도는 다른길을 찾는 것입니다.
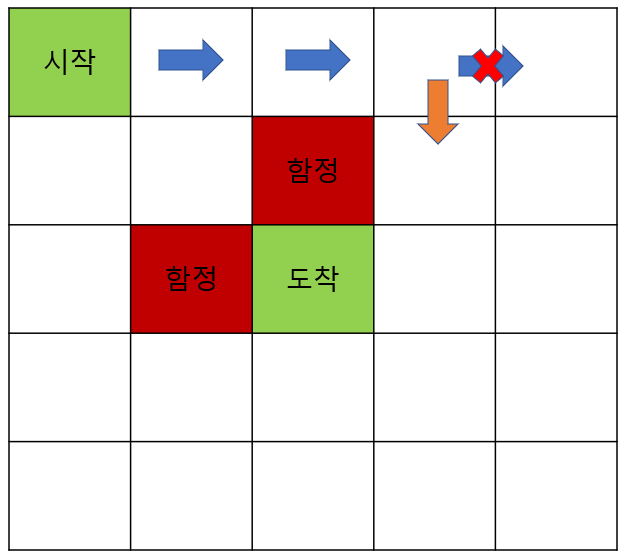
이 방식을 아래와 같이 파란 화살표가 아닌 주황 화살표로 탐험을 한다면, 도착까지 더 큰 보상을 받을 수 있는 에피소드를 에이전트는 학습 할 수 있을 것입니다. 물론 반대의 경우 더 돌아가겠지만, 충분히 많은 시도를 통해서 정답에 근사한다는 몬테 카를로 법칙에 의해 결국 정답에 근사하게 찾게될 것입니다.
- ε decaying
하지만 계속해서 ε의 확률로 학습 과정 내내 탐험(Exploration)을 지속하는 것은 학습을 저하시킬 수 있습니다. 학습 초기에는 어쩌다 성공한 에피소드에 과적합 하는것을 막아주고 새로운 루트를 찾을 수 있게 도와주는 역할이 맞습니다. 하지만 학습이 충분히 이루어진 뒤에는 학습된 가치함수만 greedy하게 따라가면 됨에도 ε의 확률로 엇나가는 역할이 되는 것이죠.
이렇듯, 탐험(Exploration)은 양날의 검같은 부분이 있습니다. 하지만 학습 초기와 말미에 특히 두드러 짐을 예상할 수 있는데요. 이때문에 ε decay라는 방식을 통해 학습 초기와 말미에 ε의 차이를 둡니다. 아래는 그 예시 중 한가지를 가져왔습니다. 아래와 같이 설정하면 iteration이 반복될때마다 ε이 줄어들 것이고, 에이전트가 탐험(Exploration)을 시도하는 확률 또한 줄어들 것을 예상할 수 있죠. 이를 Decaying ε-greedy라고 합니다.

(Decaying) ε-greedy정책은 에이전트를 탐험 시킴으로써, 최초의 보상에 과적합 되지않고, 더 나은 길을 찾기 위한 정책이라고 할 수 있겠습니다.
앞으로의 포스팅은 ε-greedy와 decaying ε-greedy을 혼용해서 사용하게 될거 같습니다.
보통은 (Decaying) ε-greedy이 생략되었다고 보시는게 좋을거 같습니다.
감사합니다.
'강화 학습' 카테고리의 다른 글
| 강화 학습 기본 - 시간차 학습(Temporal-Difference Learning) part 2. 큐 학습(Q-Leaning) (0) | 2022.01.10 |
|---|---|
| 강화 학습 기본 - 시간차 학습(Temporal-Difference Learning) part 1. 살사(SARSA) (1) | 2022.01.09 |
| 강화 학습 기본 - 몬테카를로 근사(Monte Carlo Approximation) (0) | 2022.01.06 |
| 강화 학습 기초 - 다이나믹 프로그래밍의 한계(Limitation of Dynamic programming) (2) | 2022.01.05 |
| 강화 학습 기초 - 정책(Policy), 가치 함수(Value Function) 그리고 벨만 방정식(Bellman Equation) (4) | 2022.01.05 |



