https://wikibook.co.kr/reinforcement-learning/
파이썬과 케라스로 배우는 강화학습: 내 손으로 직접 구현하는 게임 인공지능
“강화학습을 쉽게 이해하고 코드로 구현하기” 강화학습의 기초부터 최근 알고리즘까지 친절하게 설명한다! ‘알파고’로부터 받은 신선한 충격으로 많은 사람들이 강화학습에 관심을 가지
wikibook.co.kr
해당 포스팅은 위의 책을 보고 정리한 내용입니다.
2장에서는 MDP와 벨만방정식이라는 소제목으로, 앞으로 강화학습에 쓰일 개념들을 짚고 넘어갑니다.
따라서 이 장의 목표는 수식에 익숙해지고, 각 수식을 각자만의 한 줄로 이해하고,
앞으로의 내용을 보는게 좋다고 생각합니다.
들어가기 전에 에이전트와 환경을 이해해야 합니다. 저번 포스팅에 언급 했어야하는데, 제가 부족했습니다 ㅎㅎ..
강화 학습에서 에이전트는 학습의 주체입니다. 로봇이나, 사람을 생각하시면 될거같습니다. 또한 환경은 그 외 모든 에이전트에 영향을 미치는 요소들입니다. 말그대로 환경, 또는 World로 표현될 수 있을거 같습니다.
이 환경속에서 에이전트는 행동을 하고, 변화는 다음 상태와 얻게되는 보상을 관찰함으로 학습을 진행 합니다.
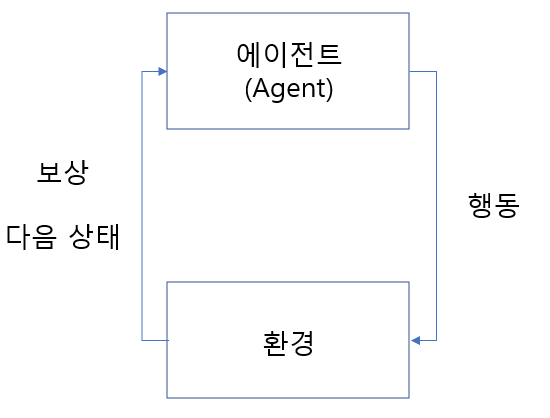
- MDP(마르코프 결정 과정, Markov Decision Process)
이제 강화 학습의 큰 개념인 MDP(마르코프 결정 과정, Markov Decision Process)을 알아보겠습니다.
"MDP는 의사결정 과정을 모델링하는 수학적인 틀을 제공한다[출처: 위키백과]."
강화학습이 이 큰그림에서 그려지고 이 요소들이 잘 정의 되어야만 좋은 결정으로 이어진다고 보시면 될거 같습니다.
그럼 각 요소들을 하나씩 살펴보겠습니다.

- 상태 S
첫 번째로는 상태(State)입니다. "상태 S는 에이전트가 관찰 가능한 상태의 집합"이라고 책에서 말합니다.
집합으로 표현되어 어리둥절 할 수 있는데 이 집합에서 현재를 t 라고 했을때 S_t는 그 집합 중 한 상태입니다.
즉 학습하고자 하는 대상이 취할 수 있는 모든 상태의 집합이 S고 현재 t에서 취하고있는, 판된되는 상태를 S_t로 나타낸다고 보시면 될거 같습니다.
간단한 예시로 사람이 자전거를 탈때 현재 어느정도 기울어져 있는지 어느정도 속도인지를 그 상태를 뜻한다고 보시면 됩니다.
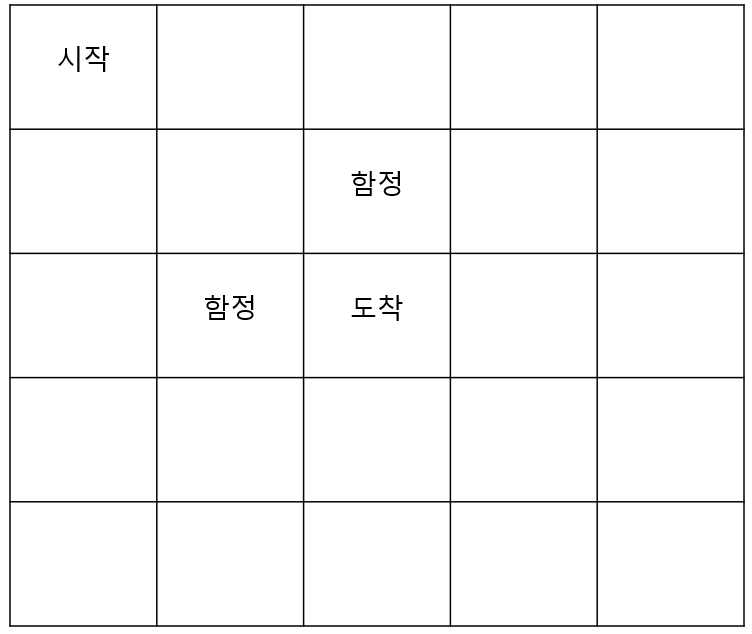
책에서와 마찬가지로 Grid world라는 것을 예시로 들텐데, 그 그림은 아래와 같습니다. 좌상단이 (1,1) 우하단이 (5,5)로 이루어져 있습니다. 여기서는 (1,1), ..., (5,5)까지 25가지 상태가 있고, 시작 했을 때(t=1), S_1 = (1,1)이 될 것입니다.
- 상태 변환 확률
순서는 바뀌었지만 상태 변환 확률 먼저 언급하고 넘어가겠습니다. 이 개념이 없으면, 조금 헷갈릴 수도 있기 때문입니다. 간단하게는 어떤 Agent(학습의 주체)가 그리드 월드에서 오른쪽으로 한 칸 이동하려고 했으나, 100% 이동하는게 아니라는 겁니다. 1%의 확률로 바람이 불어 멈춰있을 수 있고, 10%로 미끄러져 오른쪽으로 두 칸 이동 할수도 있기 때문입니다. 이러한 확률적인 요소 때문에 앞으로 나오는 수식 또한 다 확률 변수로 표현되고(아래 상태 변환 확률 수식 또한 확률 P로써 나타내짐), 그로 부터 얻는 값들 또한 기댓값 E로 표현됩니다.
개인적으로는 이러한 변수까지들도 고려하여 학습을 진행한다는 사실이 놀라웠습니다.
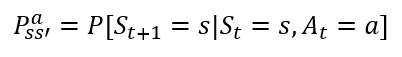
- 행동 A
행동(Action)은 어떤 상태 S_t에서 취할 수 있는 행동을 뜻합니다. 그리드 월드에서는 시작점에서 오른쪽이나 아래쪽으로 움직이는 선택지가 있을 것입니다. S_1 = (1,1)에서 취하는 행동이 오른쪽이면 A_1 = right 가 될 것이고, 다른 변수(미끄러지거나 오작동의 여지-상태 변환 확률)가 없어 반드시 행동대로 움직인다고 가정하면, S_2 = (1,2)가 될 것입니다.
- 보상 함수
보상은 에이전트가 학습할 수 있는 유일한 정보로, 환경이 에이전트에게 주는 정보입니다.
보상함수는 아래의 수식과 같이 나타낼 수 있습니다. 위에 상태 변환 확률에서 설명했듯, 상태 S_t에서 행동 A_t를 통해 다음 S_t+1이 어디인가는 확률적입니다. 따라서 어떤 A_t를 취했을 때, 보상(reward)를 얼마나 받느냐 또한 기댓값으로 표현됩니다. 참고로 그리드 월드에서 도착시 보상 R은 +1, 함정에 빠졌을 때 보상 R은 -1입니다.
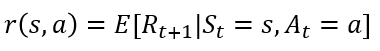
- 할인율
마지막으로, 할인율 입니다. 할인율은 감마 𝛾로 표현됩니다. 할인율은 0과 1사이의 수로(γ∈[0,1]) 같은 크기의 보상이더라도, 나중에 받을수록 가치가 줄어든다는 것입니다. 할인율은 그리드월드의 예시에서 최단거리로 도착하느냐, 최장거리로 도착하느냐를 구분 시키는 역할을 합니다. 최장 거리를 거쳐 도착하는것은 결국 더 적은 보상을 받기 때문입니다. 이는 앞으로 다른 수식에 적용된 할인율을 보면서 이해 하시게 될것입니다.
조금 더 포스팅을 할 예정이였는데, 다음 포스팅으로 넘깁니다.
이 포스팅에서는 MDP(마르코프 결정 과정, Markov Decision Process)를 알고
상태, 행동, 보상함수, 상태 변환 확률, 그리고 할인율을 알아봤습니다.
상태(S_t): t 시점에서 에이전트가 인식하고 있는 자신의 상황.
행동(A_t): t 시점에서 에이전트가 인식하고 있는 상황에서 취할 수 있는 행동.
보상 함수: 에이전트가 어떤 행동을 했을 때, 얻을 수 있는 보상, 기댓값
상태 변환 확률: S_t에서 A_t했을때 다음 상태s 일 확률.
할인율: 나중에 받을수록 보상을 줄이는 요소(factor)
감사합니다.
'강화 학습' 카테고리의 다른 글
| 강화 학습 기본 - ε-탐욕 정책(ε-greedy Policy) 그리고 ε-decay (0) | 2022.01.07 |
|---|---|
| 강화 학습 기본 - 몬테카를로 근사(Monte Carlo Approximation) (0) | 2022.01.06 |
| 강화 학습 기초 - 다이나믹 프로그래밍의 한계(Limitation of Dynamic programming) (2) | 2022.01.05 |
| 강화 학습 기초 - 정책(Policy), 가치 함수(Value Function) 그리고 벨만 방정식(Bellman Equation) (4) | 2022.01.05 |
| 강화 학습 개요 (2) | 2022.01.04 |



