결국 요즘 많이 활용되는 Text-guided Diffusion, Latent Diffusion 모델에 관한 내용
이전 글:
Diffusion 기본 논문들 간단 메모
남겨놓는 Diffusion 기본 논문들 간단 메모 Reference:https://cvpr2022-tutorial-diffusion-models.github.io/<a href="https://www.youtube.com/watch?v=uFoGaIVHfoE" target="_blan..
wnthqmffhrm.tistory.com
reference:
https://www.youtube.com/watch?v=nthpXARTduk
https://ffighting.net/deep-learning-paper-review/diffusion-model/diffusion-model-basic/
https://ffighting.net/deep-learning-paper-review/diffusion-model/stable-diffusion/
앞서 conditional diffusion에서는 c를 text로도 할 수 있다. 정확히는 text로 부터 얻어진 CLIP feature일 듯 하다.
이걸 이용해서 OpenAI에서 2021년에 먼저 GLIDE라는 논문이 나왔다.

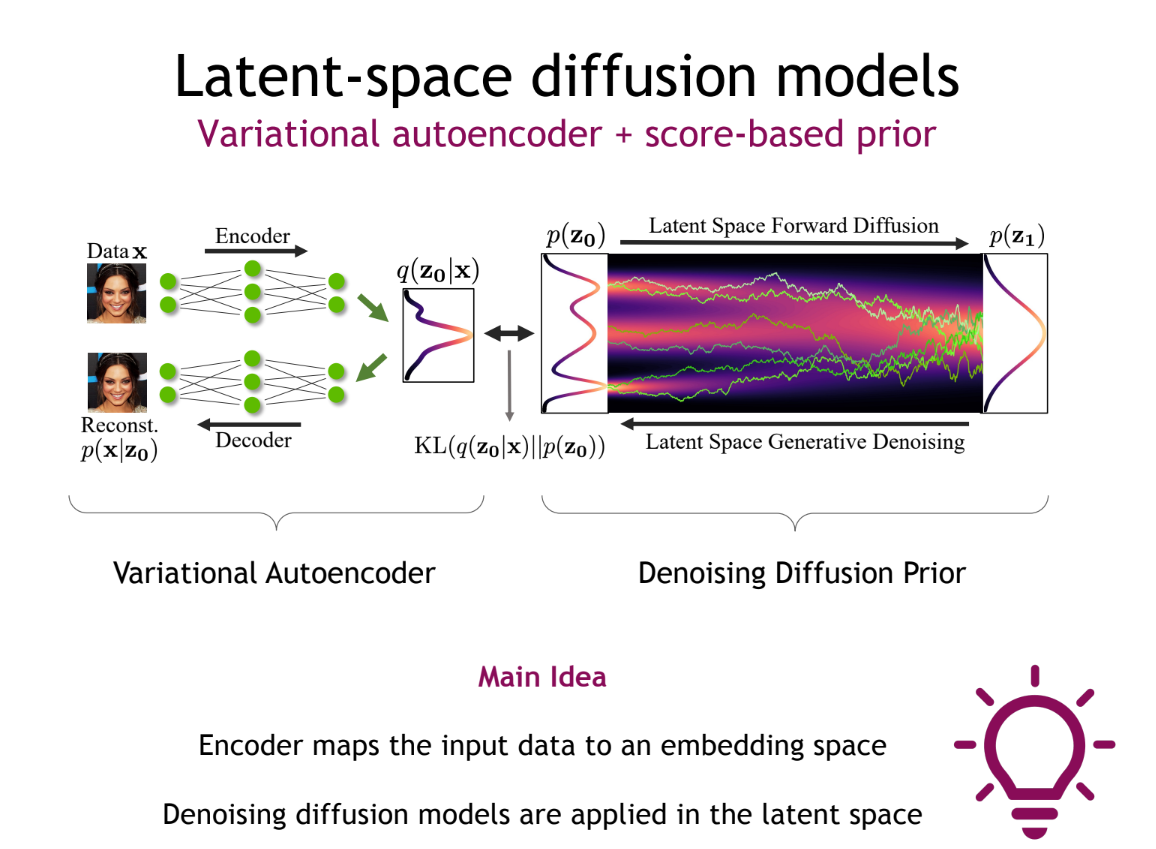
Latent-space Diffusion
여기서 latent를 이용한 diffusion을 먼저 들여다 보면, 기존 diffusion은 생성 이미지의 해상도와 같은 노이즈 맵을 활용한다는 점이 computational overhead로 작용한다. 이를 극복하기 위해 latent space, 즉 저 차원에서 diffusion process를 진행하고 decoder를 통해 다시 해상도를 높이는 연구가 진행되었다. 적절한 latent space의 학습을 위해 VAE 기술이 들어간다.
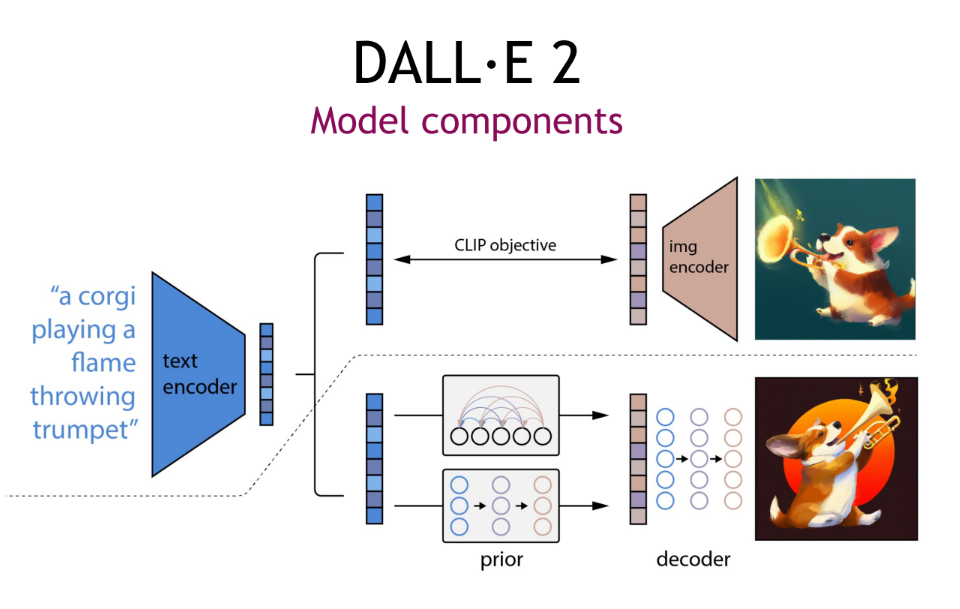
Dall-E 2
다시 돌아와서 더 발전된 모델인 Dall-E 2를 보자.
Clip latent와 Diffusion space를 매칭하여 CLIP 이미지 인코더를 통해 학습,Pair-wise text를 통해 latent-diffusion을 이용한 이미지 생성 그리고 생성된 이미지를 다시 CLIP에 넣어서 유사한(같은) feature가 나오는지 학습한다. 단지 이러한 학습으로 퍼포먼스가 나온건 아니고, 더 다양한 테크닉이 들어가있다. (혹시 보시는 분들은 큰 컨셉으로만 받아들여주세요)
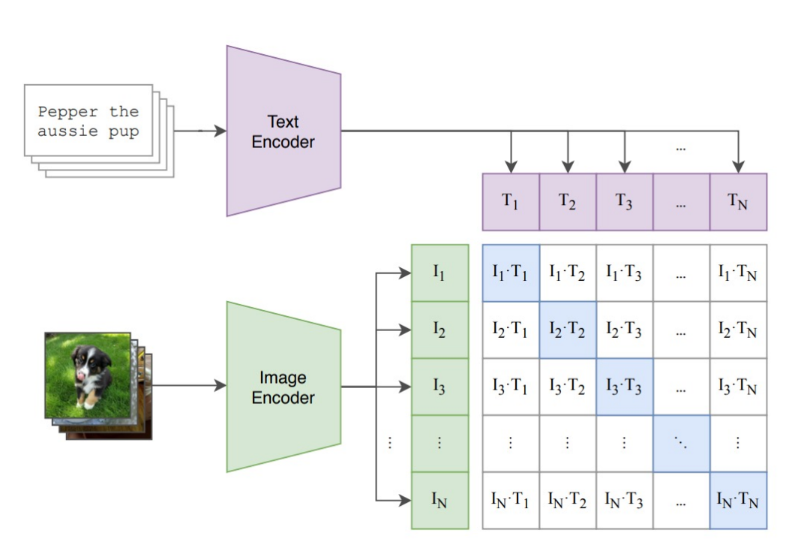
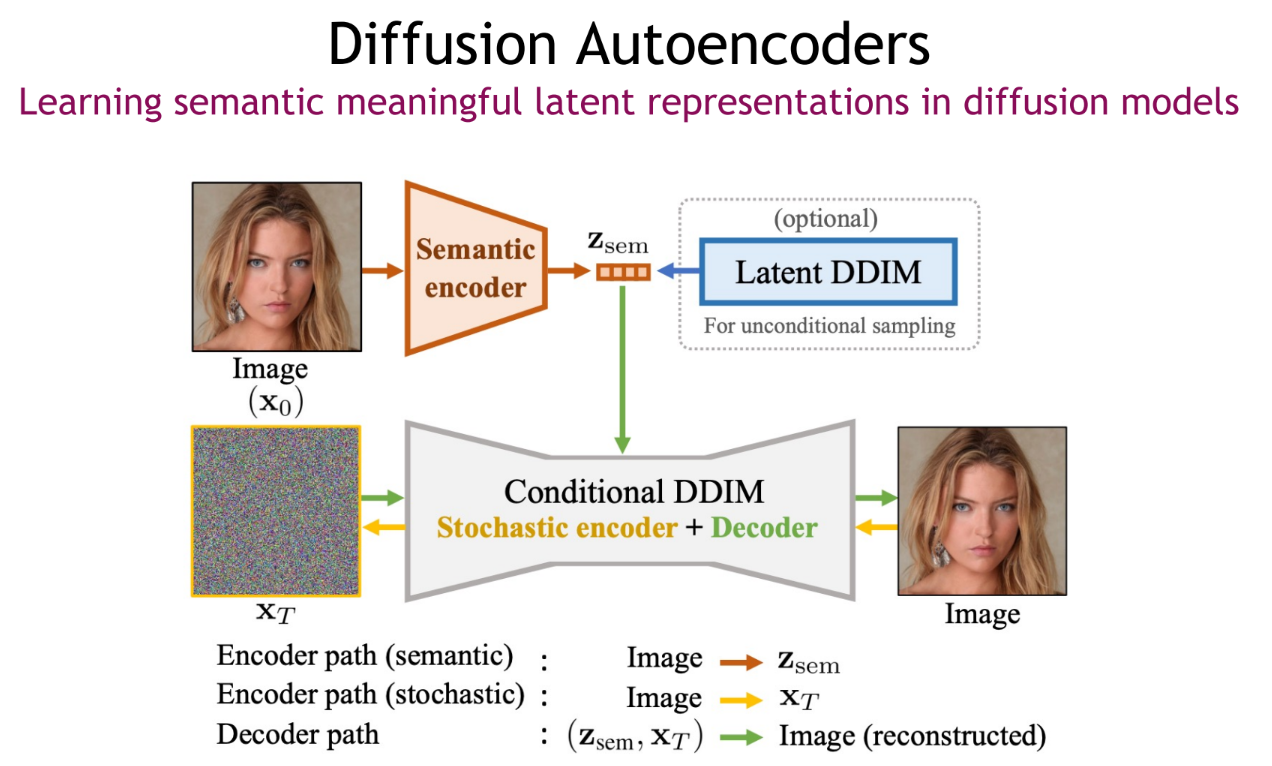
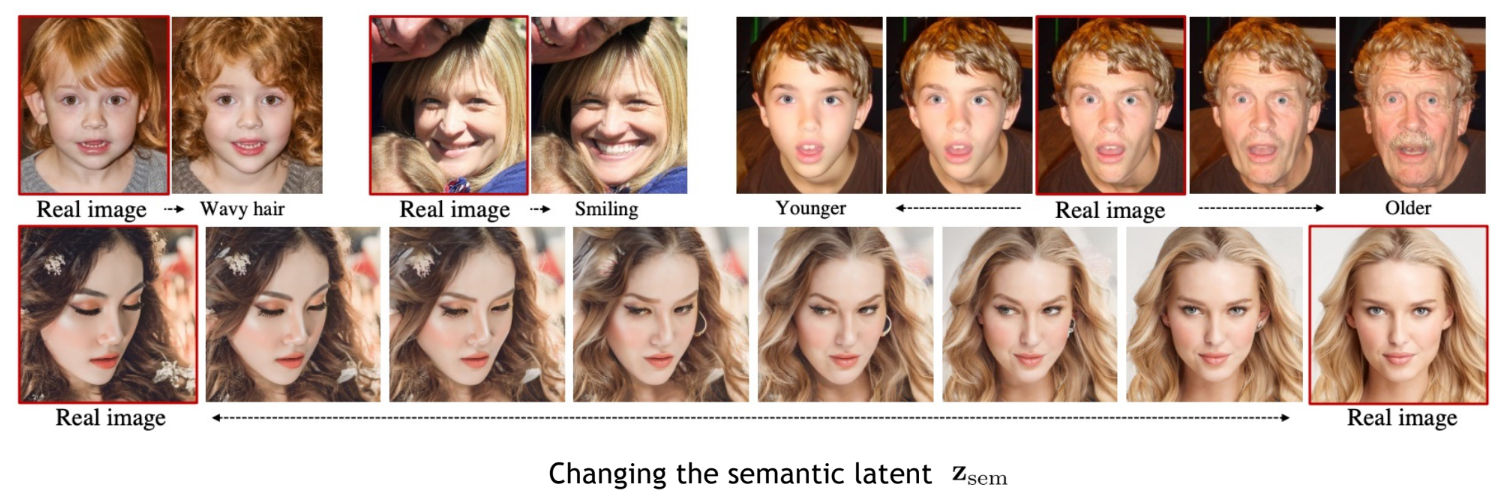
번외로, 위와 같은 text feature 방식은 에 매칭되도록 하였지만, 아래와 같이 semantic encoder를 학습하고 해당 feature에 매칭되도록 하는 방식으로 Diffusion 모델이 어떤 feature를 학습할지, 또한 애초에 controllable한 feature를 줘서 생성시에 해당 feature를 만지는 것으로 생성 이미지를 컨트롤한다.
Stable Diffusion
이제 Stable Diffusion을 보자, Latent Diffusion이라고도 불린다. 너무나도 많이 활용되는 GAN으로 따지면 StyleGAN, 을 이긴 Stable Diffusion이니 더 대단하다.

전체적인 구조는 위에 설명한 DallE2, Latent-space diffusion과 일맥상통하다. Encoder를 통해 low dimensional feature space에서 diffusion process를 진행하고 다시 decoder를 통해 최종 해상도의 이미지가 된다. 여기서 conditioning으로 나타난 우측 부분은 이전 글의 classifier-guided(free) diffusion에서와 같이 어떤 컨디션도 잘 모델링하면 diffusion process에 녹여낼 수 있다. 여기서는 classifier-free guidance를 활용한다고 한다.
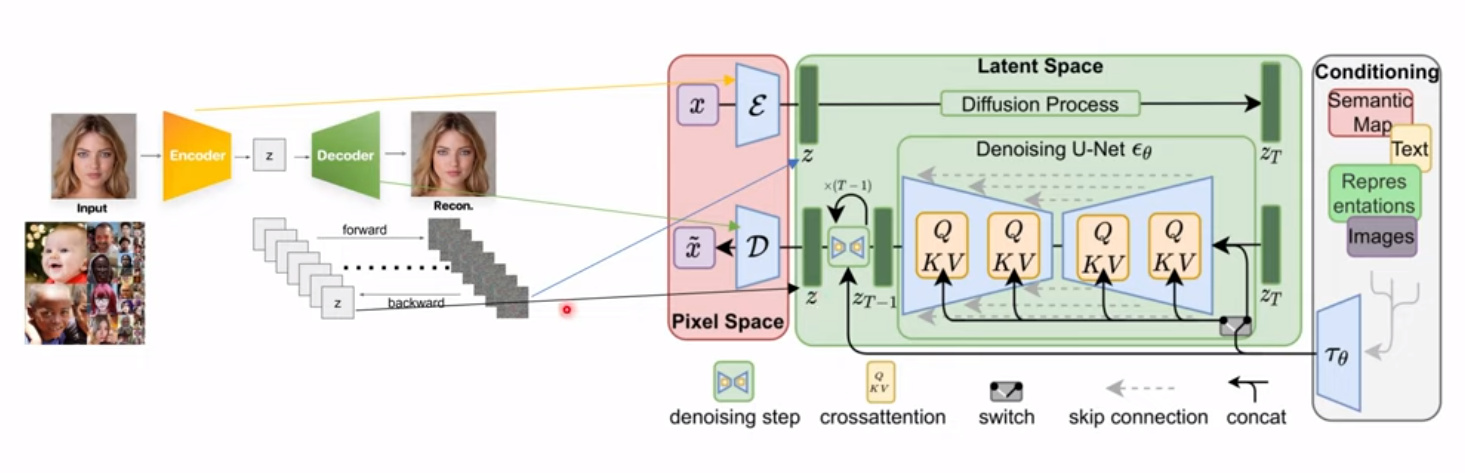
또한 Q,K,V라는 부분에 대해서 주목할 필요가 있는데, Attention 모듈을 활용하여 컨디셔닝 프로세스가 진행되는 것을 볼 수 있다. 코드를보면 더 디테일한 구조가 있다고 한다.
중요하니까 다시 정리 및 설명하면 아래와 같다.
1, 디코더와 인코더 학습.
결국 latent space에서 노이징/디노이징 하기 전 어떤 feature z를 이미지로 잘 복원시키는 디코더가 필요하다. 이를 위해 인코더 디코더를 학습시키는데, 이는 compression의 역할의 하여 작은 용량에서도 돌아갈 수 있게해주는 장점을 가지게 한다. 이를 위해 기존 pixel-wise loss뿐 아니라 patch-based discriminator를 활용한 적대적 학습 방식과 latent space의 구축을 위한 정규화 loss를 사용한다고 한다. 다른 글을 보면 VQ-VAE, VA-GAN과 같은 방식?이라고도 언급한다.
2. Diffusion process
다음으로 이렇게 학습된 latent space내에서 diffusion process가 진행되어야 할 것이다. 이러한 프로세스는 앞서 다른 프로세스들과 유사하게 U-net구조로 부터 진행되는 것으로 보여진다.
3, Conditioning
마지막으로, conditioning인데, 여기서는 cross-attention을 이용하여 Q에는 노이즈 정보, K와 V에는 condition 정보가 들어간다. 이러한 cross-attention layer를 통과한 뒤에는 U-net layer에 매핑되어 Diffusion process에 녹아드는 듯 보인다.
이때 stable diffusion에서는 test만 받을 뿐 아니라 다른 여러 컨디션도 받을 수 있다는 장점이 있다. (단, 그 중 하나의 컨디션을 받아서 이미지를 생성한다.
기존 논문들 보다 가볍고, 다양한 조건을 받을 수 있는 장점들로 인해 Stable Diffusion은 많은 홍보가 이루어지고 일반인들에게 노출되었다. 또한 이를 활용한 후속 연구들도 매우 다양하게 나오는 모습이다.



