*저는 배우는 학생이라 도메인 지식이 얕습니다. 참고 정도만 부탁드립니다.
Learning to Paint With Model-based Deep Reinforcement Learning은 ICCV 2019에서 발표된 논문입니다.
강화학습을 통해 그림을 그려주는 agent를 보여주는데요, 아래 먼저 논문 깃헙에 나와있는 결과를 가져왔습니다(맨 아래 링크). 이 그림만 봐도 논문에서 뭘 하고자 하는지는 이해하실겁니다.
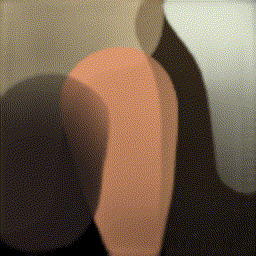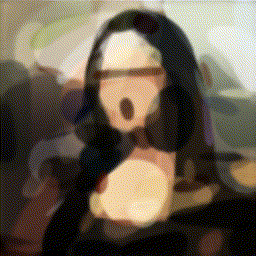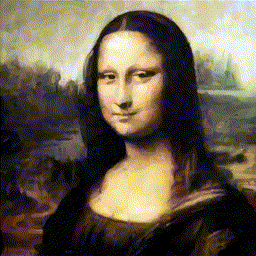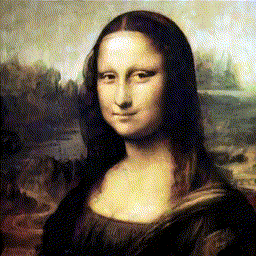
- Abstract
논문 초록에서 먼저 하고자하는 바를 언급합니다. 바로 "사람이 그리는거 처럼" 기계가 그리게 하는 것이 이 논문의 목표입니다. "진짜 사진처럼"만드는 목표하고는 다르죠.
저자들은 이를 위해 강화학습을 이용하여 에이전트가 이미지를 순차적인 storke로 할 수 있도록 합니다. 쉽게 말하면 붓을 이용해서(제한된 stroke지만) 빈 캔버스 부터 그림을 그리는 방법을 학습 시키는 것이죠.
또한 학습 단계에서는 사람이 직접 그리는 데이터나, stroke traking data가 요구되지 않습니다.
- Introduction
1문단 - 이 연구가 그림그리는 것을 도와주는 툴로써 발전될 수 있다.
2문단 - 이전 연구들은 이 논문처럼 복잡한 task를 해내지 못했다.
다음으로는 3가지 이 task가 어려운 점을 설명합니다. 사실 상 이런 점들을 극복했다는 contribution이죠.
첫번째는 사람처럼 그림을 기르는 것은 이미지를 순서된 storke로 분해할 줄 알아야한다. 즉 stroke로 밑바탕 부터 어떤 순서로 그릴지 알아야 한다는 것입니다. 여기서 가능한 방법중 하나는 지도학습 기반으로 학습을 하는 것인데, 매 순간 과정과정마다 최적의 stoke가 무엇인지 지정해 주는것은 매우 어렵죠.
또한, 하나의 그림은 stroke 한 두개가 아닌 수많은 stroke의 조합으로 표현될 수 있기 때문에 해가 여러개인 ill-definedness problem입니다. 따라서 지도학습 기반의 loss 최적화 보다 누적 보상의 합을 이용하여 학습하는 강화학습이 더 적절하다고 저자들은 주장합니다. 또한 여러 학습 기법을 추가하여 그 성능을 끌어 올립니다.
두번째는 이전 논문들에서 discrete stroke parameter spaces에서 실험을 진행했던 것과 달리 이 논문에서는 continuous stroke parameter space를 사용하였습니다. Discrete stroke parameter spaces는 stroke가 그려지는 곳을 제한하기 때문에 생성된 그림의 질을 저하시킬 수 있다고 말합니다.
마지막으로 differentiable neural renderer를 사용하여, 에이전트의 action이 환경에 어떻게 영향을 끼치는지 세부적인 feedback을 받을 수 있다고 합니다. 또한 이를 통해 end-to-end 프레임워크를 구성하여 생성 이미지와 수렴하는 학습 속도를 줄일 수 있다고 말합니다.
intro의 끝에 정리한 이 논문의 contribution은 아래와 같죠.
- model-based Deep Reinforce Learning을 통해 그림을 stroke로 분해, 그릴 수 있음.
- differentiable neural renderer를 통해 여러 storke로 그림을 그릴 수 있음, 또한 end-to-end 프레임워크로 학습에 좋은 영향
- 실험을 통해 여러 이미지들이 잘 생성될 수 있다는 것을 보임.
Related works(skip) - 이전 논문들의 한계점들을 말합니다.
3.Painting Agent
3.1 Overview(skip) - Agent는 누적 보상의 합이 최대가 되도록 학습, neural renderer는 detailed한 보상을 줄 수 있음.
3.2 The Model -
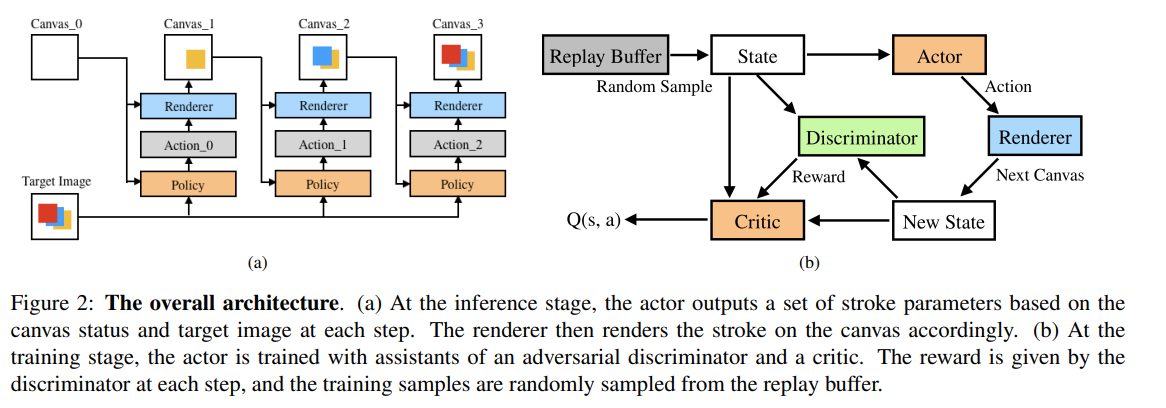
저자들은 이 문제를 Markov Decision Process로 풀어 나갔습니다. 따라서 아래 그림과 같은 요소가 필요하죠.

먼저 용어를 정리하겠습니다.
target image I
empty canvas C_0
stroke sequence (a_0, a_1, ..., a_n−1)
rendering a_t on C_t can get C_t+1
state space S, action space A
transition function trans(s_t, a_t) and a reward function r(s_t, a_t)
다음으로는 용어가 지금 문제에서 뜻하는 의미입니다.
State(상태)는s_t = (C_t, I, t)로 표현되는데, 즉 타겟이미지, 현재 canvas, 그리고 step 수로 이루어져있죠.
Transition function(상태변환확률)은 안정적인 환경이기 때문에 바로 a_t를 반영한 다음 상태를 나타내죠. s_t+1 = trans(s_t, a_t).
Action(행동)은 position, shape, color and transparency of the stroke로 구성되어 있습니다.
Reward(보상)은 agent의 학습 경향을 만들어주는 중요한 요소입니다. 저자들은 이 보상을 아래 수식과 같이 정의합니다. 이때 L_t는 I와 C_t간 계산한 loss이고, L_t+1은 I와 C_t+1과 계산한 loss이죠. 따라서 agent는 a_t를 통해 이전보다 loss가 줄어들게 행동하도록 학습하는 것입니다.
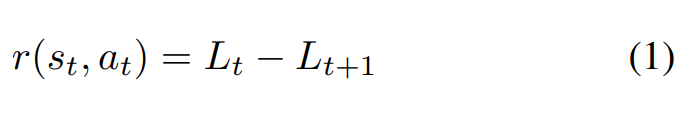
그리고 할인율(감가율, discounting factor)를 적용하여 최종 단계에서의 보상의 합은 아래 수식과 같이 표현될 수 있죠. 감가율을 적용했기 때문에 얻을 수 있는 것은 에이전트가 최소 stroke로 그림을 완성 시키도록 학습할 수 있는 것으로 보입니다. 이때 감가율의 적절한 세팅이 중요해 보이기도 하네요.
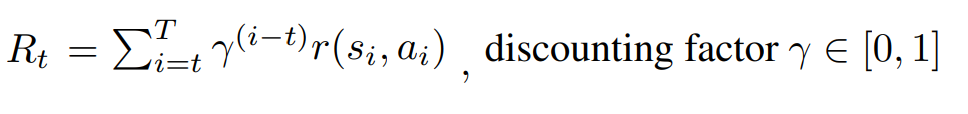
3.3 Learning
3.3.1 Model-based DDPG - 1
또한 이 논문에서는 강화학습 알고리즘인 DDPG를 사용합니다. DDPG는 Deep Deterministic Policy Gradient의 약자입니다. 여기서 Deep은 Deep Nerual Network를 사용했기 때문에 이름 붙여진 것입니다.
또한, Deterministic은 하나의 action에 대한 probability distribution이 0이 아닌 유일한 값을 가지는 경우가 그렇다고 합니다.(아래 두번째 참고한 포스팅) 위에서 Transition function(상태변환확률)을 확률적인 모델이 아닌 Deterministic으로 설정했으니 가능한 것으로 저는 이해했습니다.
Policy Gradient는 강화학습에 크게 두가지 부류가 있는데 하나는 DQN 논문으로 유명한 가치 기반 강화학습 그리고 정책 기반 강화학습입니다. Policy Gradient는 여기서 정책 기반 강화학습에 해당되죠. 앞서 continuous stroke parameter space를 사용했다고 하는데, 이 부분이 가치 기반이 아닌 정책 기반이여서 가능한 것입니다. 정책 자체를 모델링하여 학습할 수 있기 때문이죠. (가치 기반 강화학습은 은 DQN기준으로 greedy정책같이 discrete한 action에서 가장 큰 action을 선택하는 정책이기 때문에 continuous하게(확률적으로) 모델링 할 수 없습니다.)
위의 내용 중 어느 하나도 충분히 설명된 부분은 없으니 다른 포스팅이나 논문 참조 바라겠습니다. 다만 논문에 설명이 거의 없어 추가해보았습니다. 논문에서는 DPG는 high-dimensional continuous action space를 위해 사용되고, DDPG는 Neural Network을 이용한 DPG의 한 종류라고만 설명합니다.
다시 논문으로 돌아오겠습니다. DDPG는 Actor-Critic 방식을 사용하는데, 이는 상황에 대한 행동을 결정하는 정책인 actor network-π(s)와 한 행동에 대해 평가하는 critic network-Q(s,a)가 있어 두 network가 상호적으로 학습되는 방식을 취하죠. 이는 아래 수식과 같이 벨만 방정식으로 표현됩니다. 이렇게 샘플된 데이터는 DQN논문에서 제안된거 같이 replay buffer에 저장되죠.
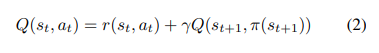
이렇게 되면 actor network는 critic network의 출력인 Q(s,a)가 가장 큰 값을 가질 수 있도록 학습합니다. 가장 가치가 높은 stroke를 만들어 내는 것이죠.
3.3.1 Model-based DDPG - 2
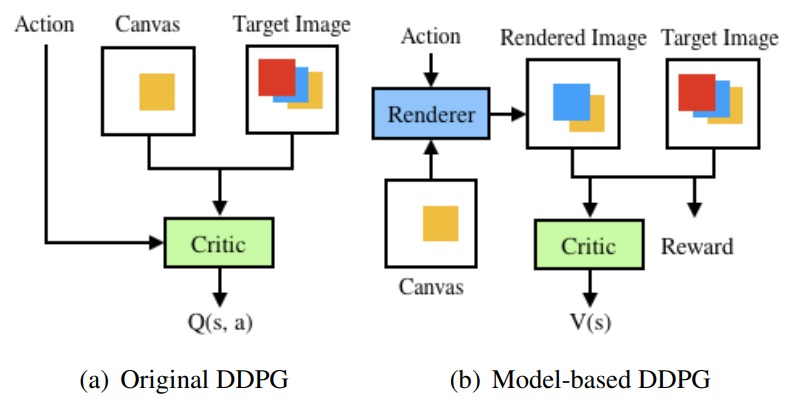
하지만 논문에서는 DDPG만으로는 좋은 성능을 낼 수 없다고 합니다. 왜냐하면 에이전트가 이 실제 이미지라는 복잡한 구성을 배울 수 없기 때문이라고 주장하죠. 그래서 원래 DDPG 알고리즘은 model-free(환경에 대한 정보 모름)알고리즘이지만, 환경을 관찰할 수 있는 model-based로 바꿔 Model-based DDPG를 제안합니다. 컴퓨터 내의 canvas를 modeling 하는 것은 real world만큼 어렵지 않으니, model-based로 접근한 것이 타당성 있어보입니다.
따라서 논문에서는 가치 함수에 대한 벨만 방정식을 아래 수식과 같이 다시 정의합니다. 아래 수식에서는 action a_t에 대한 평가 대신 state에 대한 평가만 진행되죠. 이제 actor π(s_t)는 r(s_t, π(s_t)) + V (trans(s_t, π(s_t)))를 최대화 하기위해 학습됩니다. 여기서 s_t+1 = trans(s_t, a_t)를 뜻하고 trans는 differentiable renderer가 되는 것입니다.
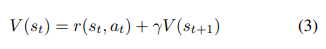
3.3.2 Action Bundle
Action Bundle은 말 그대로 행동을 한꺼번에 취하는 것입니다. 이 방식을 통해 논문에서는 연산량을 줄이고 더 좋은 성능을 달성할 수 있다고 합니다. 다시 말하자면 하나의 상황 S_t에서 k개 만큼의 action을 예측하고 순서대로 render합니다.
이는 action space의 탐험을 장려하고, 그림을 완성하는 속도, 그리고 수렴하는 속도 또한 증가시킨다고 말합니다. 또한 Action Bundle의 갯수 k = 5로 설정하였고, 순서대로 해당하는 감가율을 적용시켰습니다.
3.3.3 WGAN Reward
논문에서는 WGAN Reward를 사용하는데, WGAN은 Wasserstein GAN논문에서 제안된 방법으로 Wasserstein-l distance(=Earth-Mover distance)는 타겟 이미지의 분포와 현재 이미지의 분포를 측정하는데 적합한 측정지표라고 말합니다. 논문에서는 WGAN에 쓰인 objective function을 아래 수식과 같이 정의합니다. 이때 gradient penalty가 들어간 WGAN-GP방식을 사용한다고 말하죠.
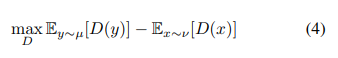
D는 discriminator를, ν 와 µ는 fake sample과 real sample의 distribution을 뜻합니다. WGAN-GP역시 설명하려면 길고 저도 잘 모르기에, 논문에서 나온대로 설명하겠습니다. 위의 수식을 보면 알 수 있듯 D는 real과 fake에 대한 차이가 크도록 학습을 진행합니다.
이렇게 학습하는 C_t일때 타겟이미지 I랑 비교해서 나온 D나온 스코어 L_t와 C_t에 a_t를 통해 나온 C_t+1을 I랑 비교해서 나온 D나온 스코어 L_t+1을 보면서 아래의 수식같이 reward가 계산되는 것이죠. (최대화 문제임으로 Lt+1이 Lt+1보다 커야합니다. 행동을 취해서 줄어든 loss가 큰 것이 reward가 크다고 하는것이죠.
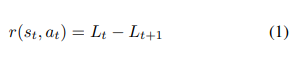
3.4. Network Architectures
사용한 네트워크는 actor와 cirtic, discriminator와 neural renderer 이렇게 총 4개입니다. 특징으로는 critic network에 Weight Normalization(WN)과 Translated ReLU(TReLU)를 사용하였습니다. 또한 critic 과 actor의 첫 레이어에 coord-conv를 넣어주었습니다.
그리고 discriminator의 구조는 PatchGAN의 구조와 비슷하게 구성하였고, 여기에도 WN과 TReLU를 사용했습니다. 또한 DDPG의 방법론을 차용하여 soft target network를 이용했다고 합니다. 이는 discriminator의 안정화에도 도움이 되었다고 말합니다.
*정확히 모르는것: WN , TReLU, soft target network
4. Stroked-based Renderer
4.1. Neural Renderer
이 논문에서는 이전과 다르게 neural network을 이용하여 Renderer를 구성하였죠. 이렇게 함으로써 두 가지 장점이 있는데, 첫번째는 여러 스타일의 stroke를 유연하게 구현 가능하다는 것입니다. 두번째로는 미분가능하기 때문에, end to end learning이 가능하게 되는 것이죠.
Neural Renderer는 사전에 학습이 되있는 것입니다. 그래픽스 프로그램을 이용해서 해당 input에 알맞은 render된 image를 출력으로 할 수 있게 사전에 학습을 진행합니다. 논문에서는 큰 어려움 없이 구현했다고 말합니다. 또한 이렇게 구현되어 있으면, model-based transition dynamics인 s_t+1 = trans(s_t, a_t)과 r_(s_t, a_t)가 모두 미분 가능해지죠.
논문에서는 또한 Neural Renderer의 구조에 upsampling layer로 pixel upsampling을 사용하였는데 이는 checkerboard 현상을 없애기 위함이라고 말합니다.
4.2. Stroke Design
방법론의 마지막 storke design입니다. stork는 position, shape, color, 그리고 transparency로 이루어져있습니다. 논문에서는 stroke를 quadratic Bezier curve(QBC)로 가정합니다. 따라서 한 stroke a_t 는 다음과 같은 성분들을 포함하게 되죠:(x0, y0, x1, y1, x2, y2, r0, t0, r1, t1, R, G, B). 여기서 (x0, y0, x1, y1, x2, y2)는 아래 수식에서 P_0, P_1, P_2를 나타내고 (r0, t0), (r1, t1)는 양 끝점의 thickness 와 transparency를 나타낸다고 합니다.
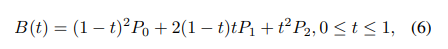
5. Experiments
간략하게 정리하고 넘어가겠습니다.
5.1. Datasets
MNIST, SVHN , CelebA 그리고 ImageNet 데이터셋 사용
5.2. Training
타겟 이미지 사이즈는 128x128
action bundle k =5
한 이미지 당 2.1초 걸림 :200 strokes on a 2.2GHz Intel Core i7 CPU. On an NVIDIA 2080Ti GPU
actor 554 MFLOPs
renderer 217 MFLOPs
40 hours for ImageNet and CelebA,
20 hours for SVHN
2 hours for MNIST
replay memory buffer -> latest 800 episodes
5.3. Results

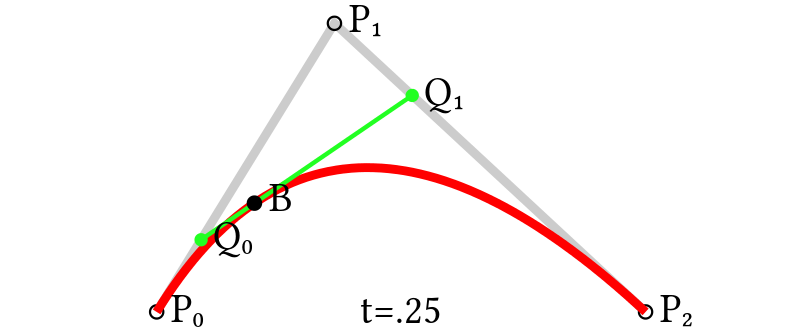
결과입니다. 우선 제 눈에는 꽤 잘 만들어내는 걸로 보입니다. 각 데이터셋마다 complexity가 다르기때문에 stroke도 조절해 준 모습을 볼 수 있습니다(사진 설명 참조).
각 데이터셋의 frame t에 대한 pixel loss는 아래 표와 같이 나타나 있죠.

또한 이전 논문인 SPIRAL(a)와 같은 stroke로 비교한 그림(b)를 봐도 모양은 좀 잘 잡는듯 보입니다. 근데 왜 같은 사진으로 비교하지 않았는지는 모르겠네요..
5.4. Ablation Studies
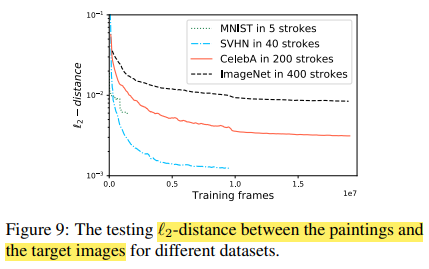
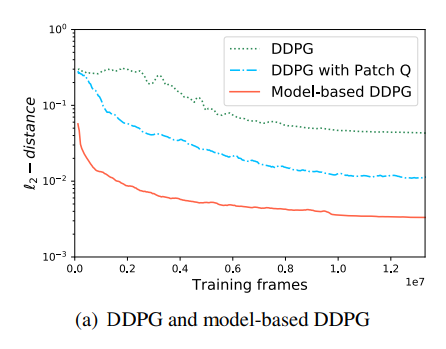
5.4.1 Model-based DDPG vs. Model-free DDPG
Model-based DDPG(빨간 실선)와 Model-free DDPG(초록 점선의 비교는 아래와 같습니다. 그 성능이 model based로 할때 훨씬 좋아진 것을 볼 수 있죠. 여기서 Patch-Q는 patch-wise로 자른 patch-level rewards로 critic을 학습한 것을 의미합니다. 이 또한 성능의 개선이 있음을 보여줍니다. 로그스케일인 점을 감안하면 큰 개선임을 알 수 있습니다.
5.4.2 Rewards
또한 l2 reward를 줬을때와 WGAN reward로 줬을 때 차이를 아래 사진과 같이 보여줍니다. 논문에서는 WGAN reward를 사용한 것이 결과적으로 test시 타겟이미지와 l2 loss를 더 줄이게 했다고 합니다.

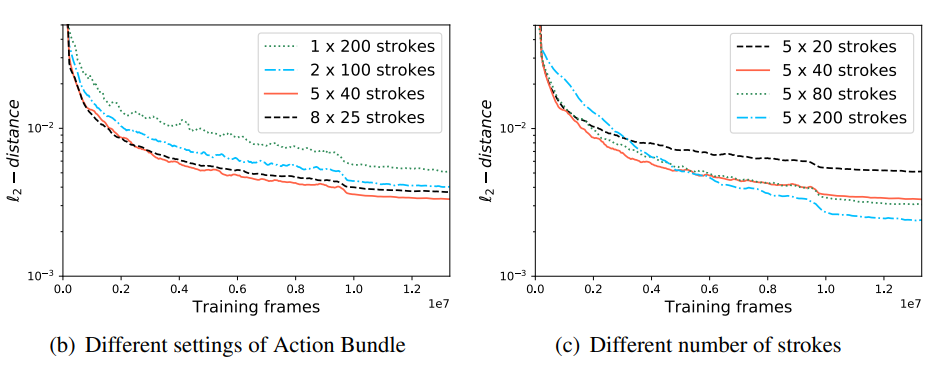
5.4.3 Stroke Number and Action Bundle
또한 성능과 Stroke Number의 숫자 그리고 성능과 Action Bundle 갯수와의 상관관계를 조사해본 결과는 아래 표와 같습니다. action bundle은 (b)와 같이 5일때가 가장 성능이 좋았고, Stroke Number는 많을수록 그 성능이 좋아짐을 확인할 수 있습니다.
5.4.4 Alternative Stroke Representations
마지막으로 다른 모양의 앞서 설명한 QBC가 아닌 stroke로 실험한 결과는 아래와 같습니다. 논문에서는 QBC가 가장 낫다고 주장하고, stroke의 특성(불투명도, 모양..)에 따라 다른 효과를 줄 수 있다고 말합니다.

6. Conclusion
사람과 같이 그리는 에이전트를 강화학습 + 논문에 나온 기법을 통해 만들어 냈습니다.
Comment:
강화학습을 이용한 생성모델이라는 개념이 생소하면서도 놀라웠습니다.
성능 자체는 놀랍지 않지만 사람처럼 그린다는 점이 논문에서도 언급되어 있지만 협업같은 용도로 발전할 수 있는 여지가 그냥 뉴럴넷 이용한 generative 모델보다 높지않나 싶습니다.
References
논문 링크:
Learning to Paint With Model-based Deep Reinforcement Learning
We show how to teach machines to paint like human painters, who can use a small number of strokes to create fantastic paintings. By employing a neural renderer in model-based Deep Reinforcement Learning (DRL), our agents learn to determine the position and
arxiv.org
GitHub 링크:
GitHub - megvii-research/ICCV2019-LearningToPaint: ICCV2019 - A painting AI that can reproduce paintings stroke by stroke using
ICCV2019 - A painting AI that can reproduce paintings stroke by stroke using deep reinforcement learning. - GitHub - megvii-research/ICCV2019-LearningToPaint: ICCV2019 - A painting AI that can repr...
github.com
참고 포스팅:
[RL] Policy Gradient Algorithms
(해당 글은 OpenAI Engineer인 Lilian Weng의 포스트 내용을 원저자 동의하에 번역한 내용입니다.) Policy Gradient Algorithms Abstract: In this post, we are going to look deep into policy gradient, why it..
talkingaboutme.tistory.com
좋은 포스팅 감사합니다.
'논문 읽기' 카테고리의 다른 글
| Diffusion 활용 논문들 간단 메모 (0) | 2024.04.29 |
|---|---|
| Diffusion 기본 논문들 간단 메모 (0) | 2024.04.29 |
| [GANInvesion + Latent space manipulation] Designing an Encoder for StyleGAN Image Manipulation, SIGGRAPH 2021 (0) | 2022.02.22 |
| [강화학습 + latent space search] Preference-Based Image Generation WACV2020 (0) | 2022.02.10 |
| [강화학습 + 이미지 처리]Exposure: A White-Box Photo Post-Processing Framework, SIGGRAPH 2018 (0) | 2022.02.10 |



