*저는 배우는 학생이라 도메인 지식이 얕습니다. 참고 정도만 부탁드립니다.
간단하게 정리하였습니다.
Preference-Based Image Generation 논문은 WACV2020에 발표된 논문입니다.
강화 학습을 이용해 원하는 이미지에 가까운 latent code를 추천해주는 agent를 학습하는 것이 목표입니다.
- 문제 정의
많은 생성 모델 연구가 진행되고 있는 가운데, fully interpretable latent code는 많지 않다. 또는 랜점 latent vector에서 생성되는 것도 많다. 따라서 latent space에서 원하는 이미지를 생성하기가 어렵다. 특히 비전문가들한테는 더더욱. 그렇게 때문에 논문에서는 preference-based reinforcement learning를 적용하여 타깃 이미지에 알맞은 latent code를 추천해주도록 학습하는 것을 목표로 한다.
논문에서는 이 문제를 해결하기위해 preference-based reinforcement learning(PbRL)를 적용하였고, 적은 수의 iteration으로 목표에 도달할 수 있도록 Model-Agnostic Meta-Learning (MAML)를 사용하였다. 이 두가지가 이 논문의 핵심인 거 같다.
- 방법론
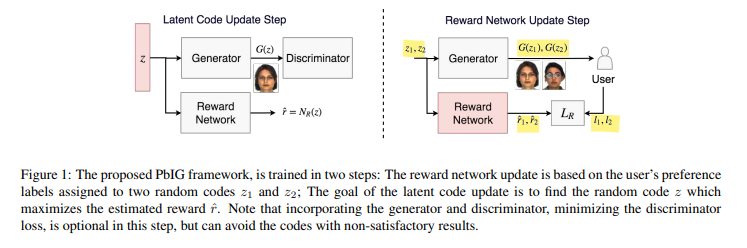
그림에서 볼 수 있듯 전체 프레임워크는 두 스텝으로 이루어져 있는데 첫 번째는 latent code를 업데이트하는 것, 두 번째는 reward network를 업데이트하는 것이다.
여기서 z1, z2를 고르는 정책은 네트워크를 따로 요구하지않고 입실론 그리디 알고리즘을 통해 결정한다. 여기서 z_last는 이전에 선택되었던 latent고 아래 _c는 정규분포를 따른다. 입실론은 학습이 지남에 따라 감소한다.
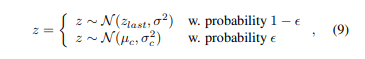
또한 weighted memory를 사용하는데 단지 memory replay를 사용하는 것이 아니라 비교적 최신의 sample이 업데이트에 더 강하게 적용되도록 weight를 주었다. ablation study를 통해 이 방법이 효과가 있음을 보였다.
Reward network는 z에 대한 reward를 예측하는 네트워크라고 보면 됩니다. 그리고 사람이 직접 피드백을 통해 그때그때 l1, l2 형식으로 1(선호), 0.5(중립), 0(비선호) 세 가지 라벨을 줍니다. 이를 이용하여 cross entropy를 계산하죠. 이때 아래와 같은 수식을 이용합니다.
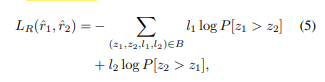
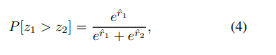
쉽게 말하면 사람의 예측과 reward의 예측이 얼마나 일치하는지를 보는 것이죠. 또한,latent code는 아래의 수식을 이용하여 reward가 최대가 되는 z를 찾습니다. 이게 샘플링할 때 Z_last에 해당합니다.

하지만 논문에서는 해당 loss만으로는 latent space가 잘 업데이트 되지 않는다고 말합니다. 여기서 discriminator loss 또한 적용되어야 업데이트가 제대로 된다고 합니다.
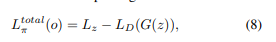
MAML을 이용하여 최적의 초기화를 찾는데요 아래의 수식을 이용해서 reward Network를 초기화 합니다. 이렇게 초기화 한 네트워크를 이용하여 위와 같이 학습을 진행하면서 추천을 하는 것으로 이해했습니다. (조금은 헷갈리네요)
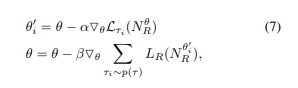
결과는 아래와 같습니다. 피드백을 진행해 가면서 점점 목표 이미지와 가까워지는 것을 볼 수 있습니다.

여기서 VGG19를 이용한 perceptual loss 와 style loss 또한 적용해서 사람의 피드백 대신 아래와 같이 라벨을 임의로 주어서도 진행해보았는데 어느 정도 의미 있는 결과가 나옵니다. 그게 위의 그림 설명에 있는 synthetic feedback 방식입니다.
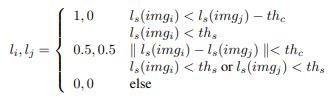
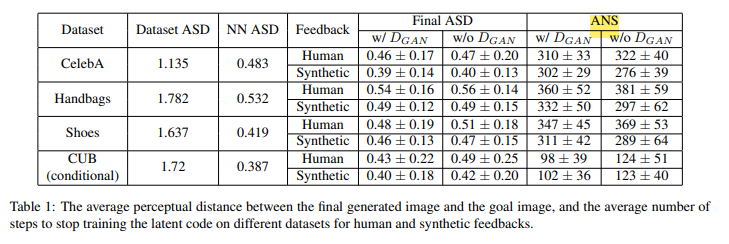
다음으로는 정량적인 평가입니다. Average Similarity Distance (ASD)라는 평가지표를 나타냈습니다. 가까울수록 비슷하다는 의미인거 같습니다. 하지만 ASD도 적합한 지표는 아니라고 말합니다. ASD상 좋은 synthetic-feedback도 사람이 보기에는 artifact가 많아 받아들이기 어려운 결과라고 말합니다. 또한 average number of steps(ANS)를 말합니다. discriminator loss를 사용하는 것이 사람이 하는 feedback에 수를 줄인다고 말합니다.
Abaltion study에서는
MAML을 쓰지않으면 average number of steps(ANS)가 증가하는 점.
Random queries를 시도해서 무작위로 더 많은 시간을 찾도록 하면 더 높은 similarity가 나오는 점
Best sample Z를 tracking하지 않으면 average number of steps(ANS)가 증가하는 점
Weighted replay memory를 사용하면 Average Similarity Distance (ASD)가 증가하는 점을 말합니다.
모든 내용을 언급한 것은 아니니 참고 부탁드립니다.
이렇게 latent space를 강화 학습 agent를 이용해 원하는 이미지와 더 가까워질 수 있음을 알 수 있었습니다.
개인적으로는 Weighted replay memory를 여기서 처음 봤는데 괜찮은 기법 중 하나인 거 같습니다.



