이 포스팅은 Part1과 이어지는 포스팅입니다.
2022.01.09 - [강화 학습] - 강화 학습 기본 - 시간차 학습(Temporal-Difference Learning) part 1. 살사(SARSA)
또한, 해당 포스팅은 아래의 책을 보고 정리한 내용입니다.
파이썬과 케라스로 배우는 강화학습: 내 손으로 직접 구현하는 게임 인공지능
“강화학습을 쉽게 이해하고 코드로 구현하기” 강화학습의 기초부터 최근 알고리즘까지 친절하게 설명한다! ‘알파고’로부터 받은 신선한 충격으로 많은 사람들이 강화학습에 관심을 가지
wikibook.co.kr
지금까지의 흐름을 간략하게 정리하겠습니다.
MDP를 통해 연속 결정 문제를 풀어야 함.
->먼저 다이나믹 프로그래밍이 제안됨.
다이나믹 프로그래밍의 한계는 막대한 계산량과 환경 변수를 모두 알아야 함.
-> 몬테카를로 근사를 통해 환경 변수를 몰라도 충분히 참 가치함수에 근접 할 수 있음
몬테카를로 근사는 에피소드가 길거나 끝이 없는 경우 학습이 곤란함.
-> SARSA라는 시간차 학습 방식으로 실시간으로 학습이 가능하게 함.
SARSA는 학습 과정 중 딜레마에 빠져 학습하는데 어려움을 겪을 수 있음.
-> 이는 On-Policy Temporal-Difference Control의 한계이다.
이 한계를 보완하는 Off-Policy Temporal-Difference Control인 Q-Learning이 이번 포스팅입니다.
위의 내용이 궁금하시다면 이전 포스팅을 참고 하시면 좋을거 같습니다.
Q-Learning은 어디서 한번쯤 들어보셨을 수도 있습니다. 아직 저도 강화학습 논문을 제대로 읽어봤다 할 순 없지만, Q-Learning이 대체로 강화학습을 한다고 하면 쓰이는 기본 방법론으로 일컬어지는 듯 합니다.
SARSA는 On-Policy였고 Q-Learning은 Off-Policy라고 합니다. 무슨 차이가 있을까요?
제가 생각한 간단한 축구 예시로 설명해보겠습니다. 아래 그림을 보면 파랑이(에이전트)가 상황 S_t에서 노란색 팀원에게 패스라는 행동 A_t를 했고 그리고 공을 받은 노랑이가 다음 상황(S_t+1)에서의 플레이(A_t+1)가 초록색 적팀의 방해로 결과적으로 실패했다고 가정해봅시다.
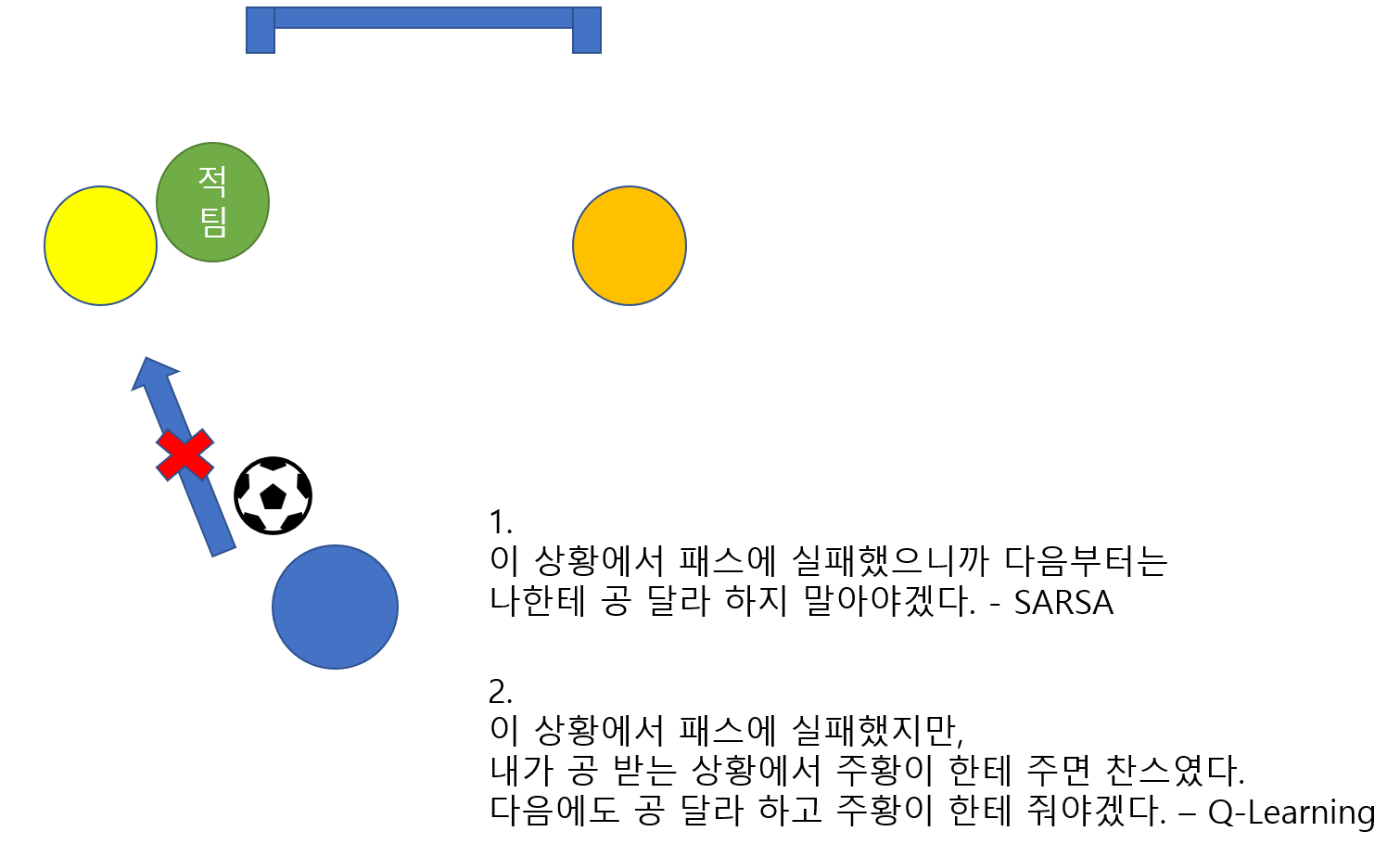
SARSA는 이와 같은 상황에서 파랑이(에이전트)가 공을 받는 상황 자체를 지양하게 됩니다. 하지만 위의 그림을 보면 주황이에게 패스를 했으면 더 좋은 찬스가 날 수 있다는 것을 생각 할 수 있습니다. 공을 받는 상황 자체가 나쁜 행동은 아닌거라고 볼 수 있죠. 따라서, 현재의 플레이(에피소드)는 어쩔수 없지만 다음 플레이부터는 공을 받은 다음 주황이 한테 주면 되는 것입니다.
위의 예시가 이해가 되시나요? 사실 수식으로 보면 더 이해가 쉬울 수도 있습니다. Q-Learning 업데이트 수식은 아래와 같습니다. 더불어, SARSA방식의 업데이트 수식도 가져왔습니다.
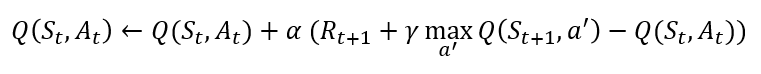
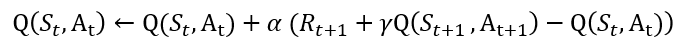
두 수식의 차이점은 SARSA에서 A_t+1이 a'으로 바뀌었다는 겁니다. 이때 a'은 S_t+1에서 가장 높은(max) 행동가치함수 값을 가지는 행동을 뜻하죠. SARSA에서는 정책에 따른 다음 행동을 고려했다면, Q-Learning에서는 최적의 다음 행동(이라고 학습된 값)을 고려합니다. 다르게 표현하면 SARSA는 이름 그대로 [S_t, A_t, R_t+1, S_t+1, A_t+1]를 고려하지만, Q-Learning은 [S_t, A_t, R_t+1, S_t+1]만을 고려합니다.
여기서 헷갈릴 수도 있는 점은 현재의 에피소드에서 에이전트의 다음 행동 A_t+1은 정책에 의해 결정될 것입니다. 다만 S_t에 대한 행동가치함수의 업데이트가 위와 같이 이루어 진다는 점입니다. 실제의 행동과 현재 상태 S_t에서 업데이트에 참고하는 행동 a'은 다를 수도 있다는 겁니다.
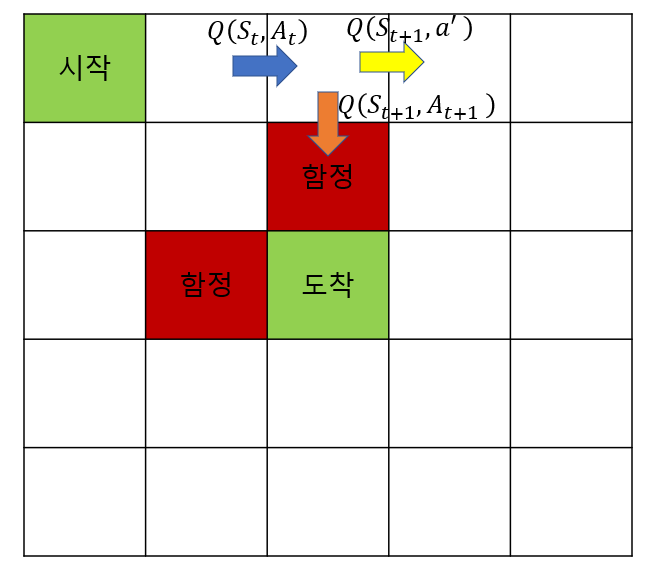
위의 그림은 이전 SARSA포스팅에서 사용했던 그림을 조금 바꾼 것입니다. SARSA는 주황색 화살표로 가는 행동을 취함으로써 파란색 화살표에 대한 가치함수 Q(S_t,A_t )가 낮아져 딜레마(직전 part1. SARSA 포스팅 참고)에 빠졌습니다. 하지만 Q-Learning시 노란색 화살표인 Q(S_(t+1),a′)를 참고하여 업데이트하기 때문에 딜레마에 빠지지 않습니다.
이번 포스팅에서는 On-Policy의 단점을 보완할 수 있는 Off-Policy의 방법인 Q-Learning을 알아보았습니다.
책에서는 큐함수를 사용하는 것이 간단하기 때문에 이후 많은 강화학습 알고리즘의 토대가 되었다고 합니다. (Q-Learning말고도 다른 Off-Policy도 있다고 언급합니다.)
감사합니다.
'강화 학습' 카테고리의 다른 글
| 강화 학습 - 정책 기반(Policy-based) 강화 학습, REINFORCE 알고리즘 (0) | 2022.01.11 |
|---|---|
| 강화 학습 - 딥 살사(Deep SARSA) 알고리즘 (0) | 2022.01.10 |
| 강화 학습 기본 - 시간차 학습(Temporal-Difference Learning) part 1. 살사(SARSA) (1) | 2022.01.09 |
| 강화 학습 기본 - ε-탐욕 정책(ε-greedy Policy) 그리고 ε-decay (0) | 2022.01.07 |
| 강화 학습 기본 - 몬테카를로 근사(Monte Carlo Approximation) (0) | 2022.01.06 |



