https://wikibook.co.kr/reinforcement-learning/
파이썬과 케라스로 배우는 강화학습: 내 손으로 직접 구현하는 게임 인공지능
“강화학습을 쉽게 이해하고 코드로 구현하기” 강화학습의 기초부터 최근 알고리즘까지 친절하게 설명한다! ‘알파고’로부터 받은 신선한 충격으로 많은 사람들이 강화학습에 관심을 가지
wikibook.co.kr
해당 포스팅은 위의 책을 보고 정리한 내용이 주를 이룹니다.
또한, 이 포스팅에서 Neural Network(Deep Learning)에 대해서는 따로 설명하지 않겠습니다.
2022.01.11 - [강화 학습] - 강화 학습 - 정책 기반(Policy-based) 강화 학습, REINFORCE 알고리즘
2022.01.12 - [강화 학습] - 강화 학습 - DQN
2022.01.13 - [강화 학습] - 강화 학습 - A2C(Actor-Critic), Continuous A2C
현재 포스팅과 관련된 포스팅은 위와 같습니다. 또한, 이번 포스팅은 스레드(Thread)라는 Operating System 지식이 요구됩니다.
Asynchronous Advantage Actor-Critic(이하 A3C)가 고안된 배경은 DQN과 (Continuous) A2C의 특징을 보면 이해가 쉽습니다.
- (Continuous) A2C
- On-Policy 기반 정책 기반 강화 학습
- 실시간으로 학습 가능, 하지만 샘플 간 correlation 문제 有, 때문에 복잡한 문제에 대한 학습이 어려움.
- 정책 자체를 학습시킬 수 있어 유연한 정책 학습 가능(ex. Continuous A2C)
- DQN
- Off-Policy 기반 Q-Learning 기반 강화 학습
- 리플레이 메모리를 사용한 샘플 간 correlation 샘플 간 correlation 극복
- 많은 메모리 소모, 느린 학습 속도
이렇게 나열해보면 두 방법의 장단점이 확실히 보입니다. A2C의 문제는 샘플 간 correlation 문제이고 DQN의 문제는 리플레이 메모리를 사용하기 때문에 많은 Computation power가 요구된다는 것과 실시간으로 학습이 불가능 하다는 것입니다. 따라서 오늘 소개할 A3C에는 리플레이 메모리를 사용하지 않으면서 A2C에 샘플간 correlation 문제를 극복할 수 있는 방법을 제시합니다. 바로 Mutli Thread의 사용으로 여러 하위 에이전트를 Asynchronous(비동기식)으로 작동시키는 것이죠.
먼저 전체 학습도를 보여드리겠습니다. 아래 각 환경에서 Actor-Learner라고 불리는 각 모델들이 에피소드를 진행합니다. 이때 각 환경은 독립되어있기 때문에, 에피소드 간 correlation은 거의 없죠. 이렇게 각 환경에서 Actor-Learner가 일정 타임 스텝 동안의 샘플을 가지고 글로벌 신경망을 업데이트합니다(파란색 화살표). 또한 이렇게 학습한 글로벌 신경망의 파라미터를 Actor-Learner와 일치시킨 뒤, 각 Actor-Learner가 또다시 독립적인 에피소드를 수행하여 샘플을 모으는 과정을 반복하죠.
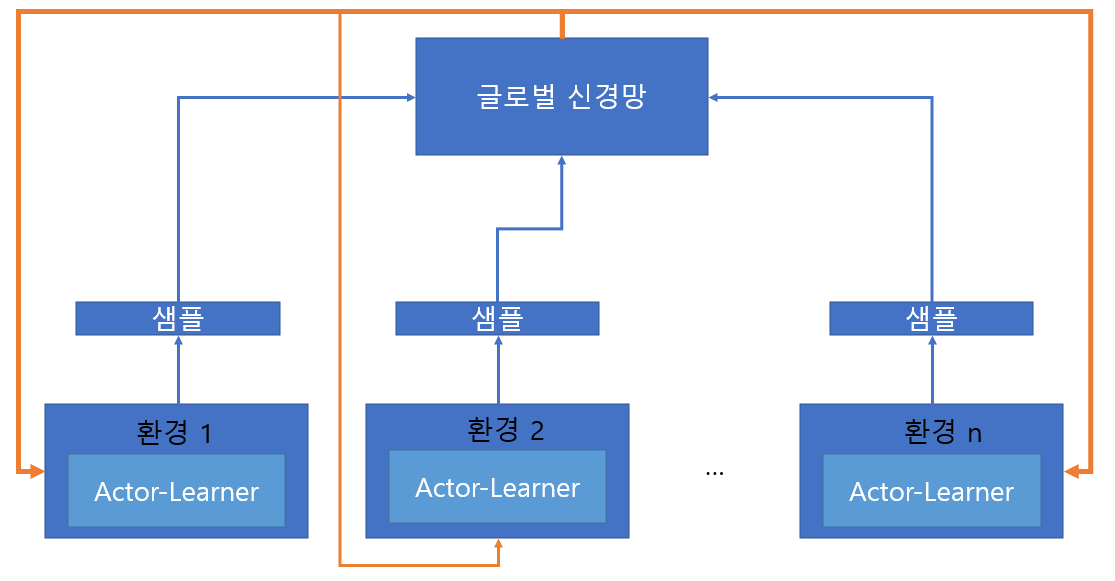
위의 아이디어가 A3C의 핵심입니다. Asynchronous 한 Actor-Learner들과 글로벌 신경망을 이용하여 어느 정도 실시간이지만, 글로벌 신경망이 학습하는 샘플 간 correlation을 감소시켜 A2C에서의 나타났던 문제점을 해결한 것이죠. 책에서는 그 과정을 아래와 같이 정리합니다.
1. 글로벌신경망의 생성과 여러 개의 환경 및 Actor-Learner 생성
2. 각 Actor-Learner는 일정 타임 스텝동안 에피소드를 독립적으로 진행하면서 샘플을 저장
3. 일정 타임 스텝 후, Actor-Learner들이 모은 샘플로 글로벌신경망 업데이트
4. Actor-Learner는 업데이트된 글로벌신경망으로 자신을 업데이트여기까지 이해하셨으면, 책에서 설명하는 A3C의 콘셉트는 다 이해하신 겁니다. 하지만 책에서는 코드 구현 상 많은 디테일 설명이 있으므로 요구에 따라 코드를 보실 것을 추천드립니다(참고로 코드는 오픈돼있습니다). 책에 나온 언급할만한 디테일을 말씀드리고 포스팅을 마치려고 합니다.
- 엔트로피(Entropy)의 사용
A3C에는 특이하게 엔트로피가 정책에 대한 오류 함수에 추가로 더해집니다. 이전에 크로스 엔트로피를 사용해서 표현했던 A2C의 경우와는 다릅니다. 엔트로피(정보 이론에서 나오는 개념)는 모든 경우에 대해 균등한 분포(uniform distribution)를 가질수록 높은 값을 가집니다. 어느 쪽으로든 결정적이지 않기 때문에 엔트로피(복잡한 정도)가 커진다고 이해하시면 좋을 거 같습니다.
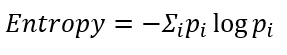
코드 상에서는 부호를 바꾸어 사용합니다. 즉 -Entropy 값을 사용하게 되는데, 이렇게 되면 위에 설명한 것과 반대로 균등한 분포를 가질수록 값이 작아지죠. 따라서 부호를 바꾼 엔트로피를 오류 함수에 더해주면 해당 항이 작아지도록 학습해야 하므로 행동을 결정하는 분포가 균등해지도록 학습을 진행할 것입니다.
행동을 결정하는 분포가 균등하게 된다는 것은 행동의 선택이 랜덤 하게 된다는 것입니다. 그럼 학습을 저하시키죠. 왜 이런 항을 일부러 넣었을까요? 바로 탐험을 유도하기 위해서라고 설명합니다. -Entropy 항이 정책 신경망이 수렴하는 것을 방해하면서 탐험을 통해 더 다양한 샘플을 가질 수 있도록 유도하는 것이죠. 하지만 너무 탐험이 강조되면 학습이 저해되므로 책에서는 0.01을 곱한 값을 사용합니다. 하나의 Actor-Learner 1만으로 업데이트를 한다고 가정했을 때, 업데이트 수식은 아래와 같이 표현될 수 있습니다.
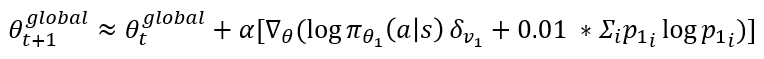
- 학습의 경향성
또 책에서는 학습이 잘 되고 있는지 아닌지를 어떻게 판단하는지 친절하게 설명해줍니다. 바로 정책 신경망의 출력의 최댓값이 1에 가까워질 때의 성능을 보는 것인데요. 출력의 최댓값이 1에 가까워진다는 의미는 정책 신경망이 수렴해서 어떤 특정 정책을 학습했다는 것을 의미합니다. 어떤 상태에 대한 행동이 결정적이라는 것이니까요. 이 상황에서 문제에 대한 성능(reward)이 좋다면 최적의 정책에 가깝게 수렴한 것이고, 아니라면 학습이 잘못되어 좋지 않은 정책에 수렴했다는 것을 의미하기 때문입니다.
또한 DQN과 비교해 봤을 때, 최종 성능은 비슷하지만, 같은 성능을 얻기 위한 시간이 DQN은 40시간이 걸리는데 비해 A3C는 26시간 만에 도달했다고 합니다. 이는 앞서 말한 DQN의 느린 학습 속도를 개선한 것이라고 볼 수 있습니다.
책의 마지막에 있는 A3C가 2016년 논문이라니.. 지금 2022년에 6년이라는 시간 동안 또 얼마나 많은 논문이 나왔을까요? 아직 가야 할 길이 먼 거 같습니다..
이로써 책 한 권에 대한 포스팅이 모두 끝났습니다.
감사합니다.
'강화 학습' 카테고리의 다른 글
| [개념만] Hierarchical Deep Reinforcement Learning (0) | 2022.02.12 |
|---|---|
| 강화 학습 - A2C, Continuous A2C (2) | 2022.01.13 |
| 강화 학습 - DQN (1) | 2022.01.12 |
| 강화 학습 - 정책 기반(Policy-based) 강화 학습, REINFORCE 알고리즘 (0) | 2022.01.11 |
| 강화 학습 - 딥 살사(Deep SARSA) 알고리즘 (0) | 2022.01.10 |


